
import pandas as pd
import numpy as np
# Muat dataset
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rainy', 'rainy', 'rainy', 'overcast',
'sunny', 'sunny', 'rainy', 'sunny', 'overcast', 'overcast', 'rainy',
'sunny', 'overcast', 'rainy', 'sunny', 'sunny', 'rainy', 'overcast',
'rainy', 'sunny', 'overcast', 'sunny', 'overcast', 'rainy', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0,
72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0,
88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0,
90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0,
65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True,
True, False, True, True, False, False, True, False, True, True, False,
True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes',
'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes',
'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
# Pra-pemrosesan data
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
df['Wind'] = df['Wind'].astype(int)
# Tentukan label
X, y = df.drop('Play', axis=1), df['Play']Sumber: Artikel ini diterjemahkan dan ditulis ulang dari tulisan asli oleh Samy Baladram yang diterbitkan di TDS Archive: Model Validation Techniques, Explained: A Visual Guide with Code Examples
Setiap hari, mesin membuat jutaan prediksi — mulai dari mendeteksi objek dalam foto hingga membantu dokter menemukan penyakit. Namun sebelum mempercayai prediksi-prediksi tersebut, kita perlu tahu apakah prediksinya sudah benar. Tentu saja, tidak ada yang mau menggunakan mesin yang salah hampir setiap saat!
Di sinilah validasi berperan penting. Metode validasi menguji prediksi mesin untuk mengukur seberapa andal hasilnya. Meskipun kedengarannya sederhana, ada berbagai pendekatan validasi yang masing-masing dirancang untuk menangani tantangan spesifik dalam machine learning.
Di sini, penulis asli telah mengorganisasikan 12 teknik validasi ini dalam struktur pohon (tree), memperlihatkan bagaimana teknik-teknik tersebut berkembang dari konsep dasar menjadi konsep yang lebih khusus. Tentu saja, setiap metode akan dijelaskan dengan visual yang jelas dan dataset yang konsisten untuk menunjukkan apa yang dilakukan masing-masing metode dan mengapa pemilihan metode itu penting.
1 Apa itu Validasi Model?
Validasi model adalah proses pengujian seberapa baik model machine learning bekerja dengan data yang belum pernah dilihat atau digunakan selama pelatihan. Pada dasarnya, kita menggunakan data yang sudah ada untuk memeriksa performa model, bukan menggunakan data baru. Ini membantu kita mengidentifikasi masalah sebelum model digunakan secara nyata.
Ada beberapa metode validasi, dan setiap metode memiliki kelebihan spesifik serta mengatasi tantangan validasi yang berbeda:
- Metode validasi yang berbeda dapat menghasilkan hasil yang berbeda pula, sehingga memilih metode yang tepat itu penting.
- Beberapa teknik validasi bekerja lebih baik untuk jenis data dan model tertentu.
- Menggunakan metode validasi yang salah dapat memberikan hasil yang menyesatkan tentang performa model yang sebenarnya.
Berikut adalah diagram pohon yang menunjukkan bagaimana metode-metode validasi ini saling berhubungan:
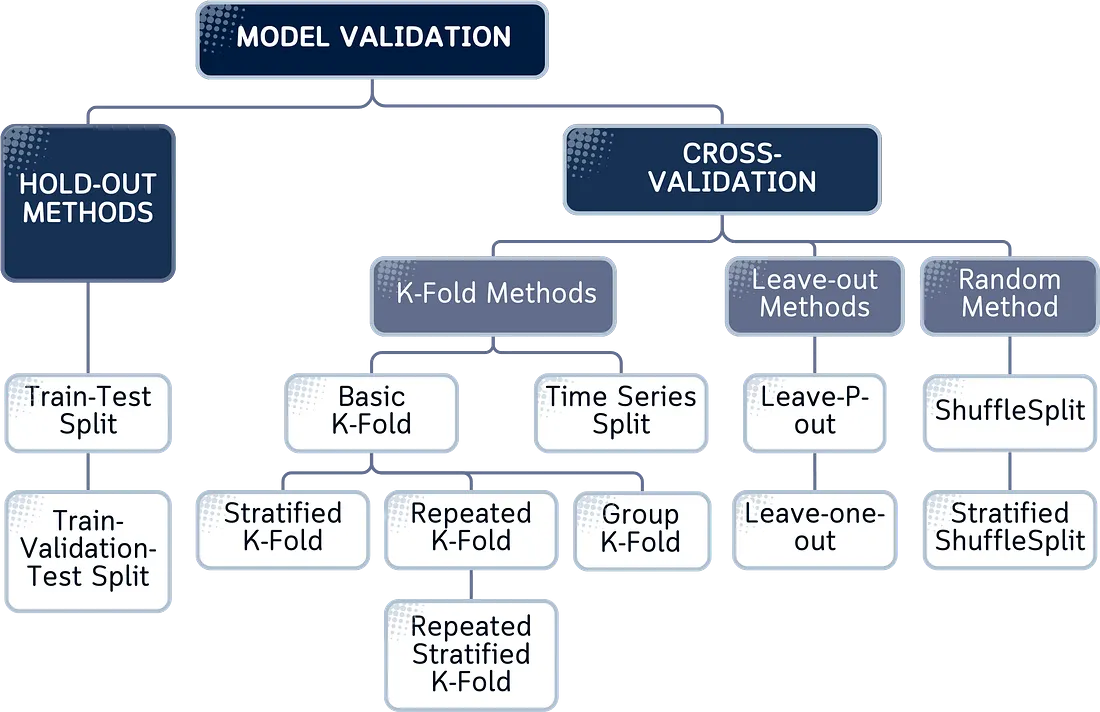
Selanjutnya, kita akan melihat setiap metode validasi lebih dekat dengan menunjukkan cara kerjanya secara tepat. Untuk mempermudah pemahaman, kita akan menggunakan contoh-contoh yang jelas yang memperlihatkan cara kerja metode-metode ini dengan data nyata.
2 Contoh yang Digunakan
Kita akan menggunakan contoh yang sama di seluruh artikel untuk membantu memahami setiap metode pengujian. Meskipun dataset ini mungkin tidak cocok untuk beberapa metode validasi, menggunakan satu contoh yang sama memudahkan perbandingan antar metode yang berbeda dan melihat cara kerja masing-masing.
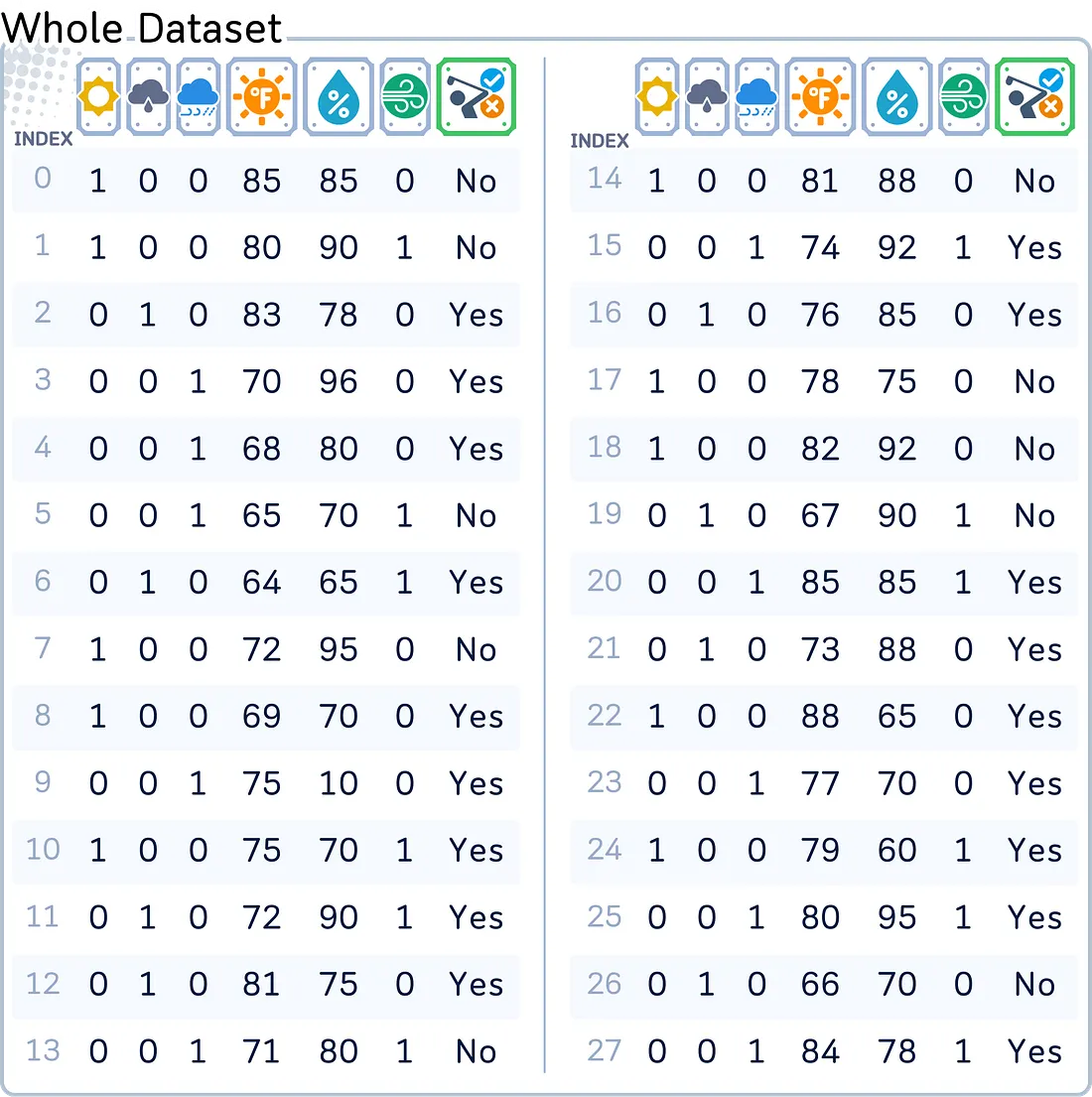
2.1 📊 Dataset Golf
Kita akan menggunakan dataset yang memprediksi apakah seseorang akan bermain golf berdasarkan kondisi cuaca.
Kolom yang ada: Outlook (dikodekan menjadi 3 kolom one-hot), Temperature (dalam Fahrenheit), Humidity (dalam %), Windy (Ya/Tidak), dan Play (Ya/Tidak, sebagai target).
2.2 Model yang Digunakan
Kita akan menggunakan decision tree classifier untuk semua pengujian. Model ini dipilih karena hasilnya dapat dengan mudah digambarkan sebagai struktur pohon, di mana setiap cabang menunjukkan keputusan yang berbeda. Untuk menjaga kesederhanaan dan fokus pada cara pengujian model, kita akan menggunakan parameter default scikit-learn dengan random_state yang tetap.
Mari kita perjelas dua istilah yang akan sering digunakan. Decision tree classifier adalah algoritma pembelajaran yaitu metode yang menemukan pola dalam data kita. Ketika kita memasukkan data ke dalam algoritma ini, ia menciptakan sebuah model (dalam hal ini, pohon dengan cabang-cabang yang jelas menunjukkan keputusan berbeda). Model inilah yang sebenarnya akan kita gunakan untuk membuat prediksi.
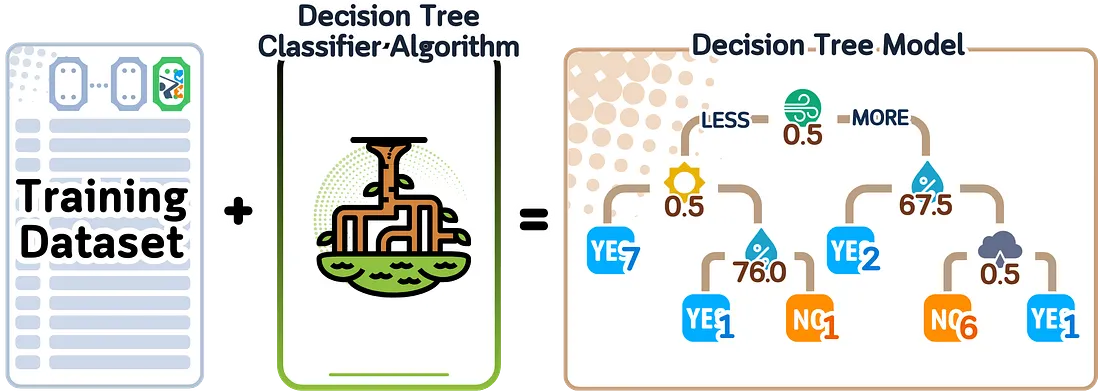
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
dt = DecisionTreeClassifier(random_state=42)Setiap kali kita membagi data secara berbeda untuk validasi, kita akan mendapatkan model yang berbeda dengan aturan keputusan yang berbeda pula. Setelah validasi kita menunjukkan bahwa algoritma bekerja dengan andal, kita akan membuat satu model akhir menggunakan semua data. Model akhir inilah yang benar-benar akan digunakan untuk memprediksi apakah seseorang akan bermain golf atau tidak. Dengan pengaturan ini siap, kita sekarang dapat fokus memahami cara kerja setiap metode validasi.
3 Metode Hold-out
Metode hold-out adalah cara paling dasar untuk memeriksa seberapa baik model kita bekerja. Pada metode ini, kita menyimpan sebagian data khusus hanya untuk pengujian.
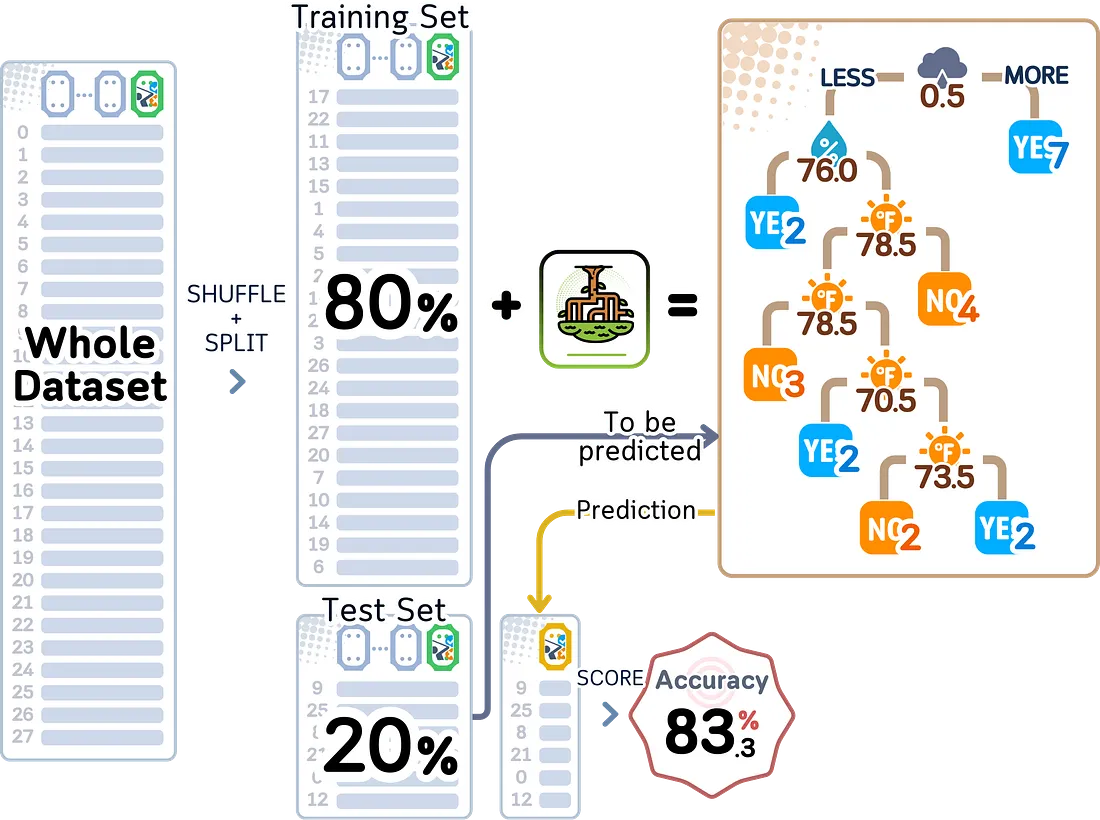
3.1 Train-Test Split
Metode ini sederhana: kita membagi data menjadi dua bagian. Satu bagian digunakan untuk melatih model dan bagian lainnya untuk mengujinya. Sebelum membagi data, kita mengacaknya secara acak agar urutan data asli tidak memengaruhi hasil.
Ukuran dataset pelatihan dan pengujian bergantung pada ukuran total dataset kita, biasanya dinyatakan dengan rasionya. Berikut panduan untuk menentukan ukurannya:
- Dataset kecil (~1.000–10.000 sampel): gunakan rasio 80:20
- Dataset sedang (~10.000–100.000 sampel): gunakan rasio 70:30
- Dataset besar (>100.000 sampel): gunakan rasio 90:10
from sklearn.model_selection import train_test_split
# Bagi data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Latih dan evaluasi
dt.fit(X_train, y_train)
test_accuracy = dt.score(X_test, y_test)
# Plot pohon
plt.figure(figsize=(5, 5), dpi=150)
plot_tree(dt, feature_names=X.columns, filled=True, rounded=True)
plt.title(f'Train-Test Split (Akurasi Test: {test_accuracy:.3f})')
plt.tight_layout()
plt.show()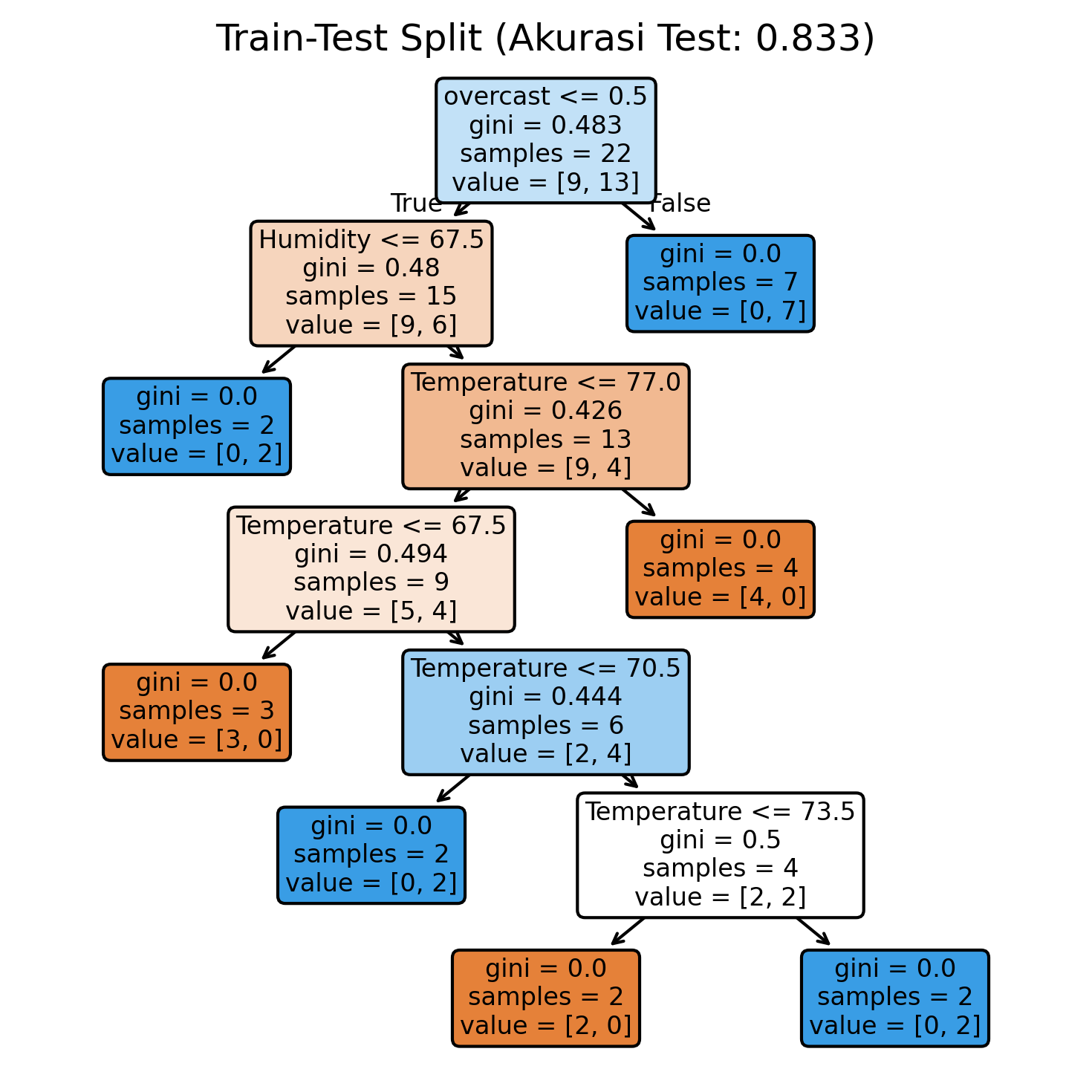
Metode ini mudah digunakan, tetapi memiliki keterbatasan — hasilnya dapat berubah banyak tergantung pada cara kita secara acak membagi data. Itulah mengapa kita selalu perlu mencoba random_state yang berbeda untuk memastikan hasilnya konsisten. Selain itu, jika data kita tidak banyak, kita mungkin tidak memiliki cukup data untuk melatih atau menguji model dengan baik.
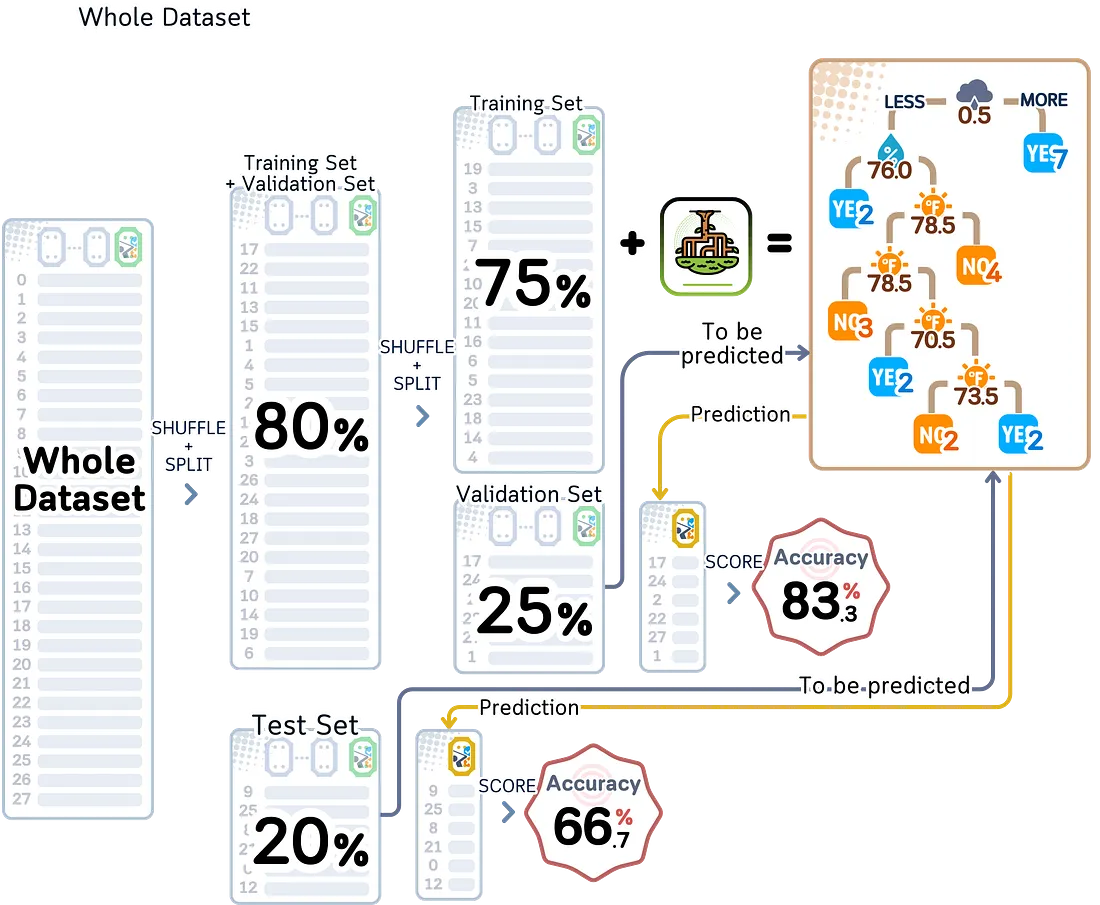
3.2 Train-Validation-Test Split
Metode ini membagi data menjadi tiga bagian. Bagian tengah, yang disebut data validasi, digunakan untuk menyetel parameter model dengan tujuan meminimalkan kesalahan di sana.
Karena hasil validasi dipertimbangkan berkali-kali selama proses penyetelan ini, model kita mungkin mulai terlalu baik pada data validasi. Itulah alasan mengapa kita membuat set pengujian yang terpisah. Kita hanya mengujinya sekali di akhir — ini memberikan gambaran sebenarnya tentang seberapa baik model kita bekerja.
Cara umum membagi data:
- Dataset kecil (1.000–10.000 sampel): rasio 60:20:20
- Dataset sedang (10.000–100.000 sampel): rasio 70:15:15
- Dataset besar (>100.000 sampel): rasio 80:10:10
# Pembagian pertama: pisahkan set pengujian
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Pembagian kedua: pisahkan set validasi
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp, test_size=0.25, random_state=42
)
# Latih dan evaluasi
dt.fit(X_train, y_train)
val_accuracy = dt.score(X_val, y_val)
test_accuracy = dt.score(X_test, y_test)
# Plot
plt.figure(figsize=(5, 5), dpi=150)
plot_tree(dt, feature_names=X.columns, filled=True, rounded=True)
plt.title(f'Train-Val-Test Split\nAkurasi Validasi: {val_accuracy:.3f}'
f'\nAkurasi Test: {test_accuracy:.3f}')
plt.tight_layout()
plt.show()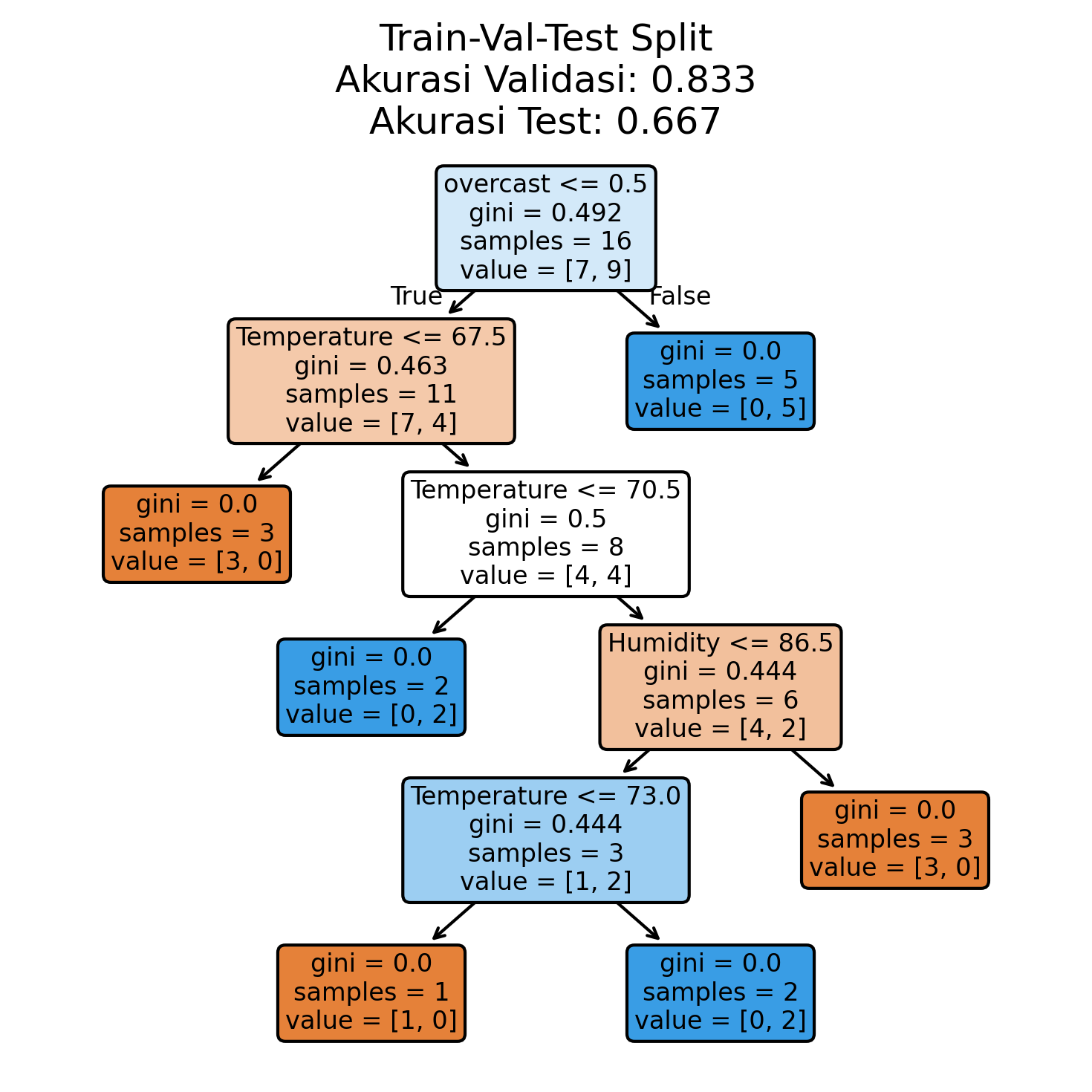
Metode hold-out bekerja secara berbeda tergantung pada jumlah data yang dimiliki. Metode ini sangat baik ketika memiliki banyak data (>100.000). Namun ketika data lebih sedikit (<1.000), metode ini mungkin bukan yang terbaik. Dengan dataset yang lebih kecil, kita mungkin perlu menggunakan metode validasi yang lebih canggih untuk memahami seberapa baik model kita benar-benar bekerja.
3.3 📊 Beralih ke Cross-validation
Kita baru saja mempelajari bahwa metode hold-out mungkin tidak bekerja dengan baik untuk dataset kecil. Inilah tantangan yang kita hadapi sekarang — kita hanya memiliki 28 hari data. Mengikuti prinsip hold-out, kita akan menyimpan 14 hari data secara terpisah untuk pengujian akhir. Ini menyisakan 14 hari untuk dicoba dengan metode validasi lainnya.
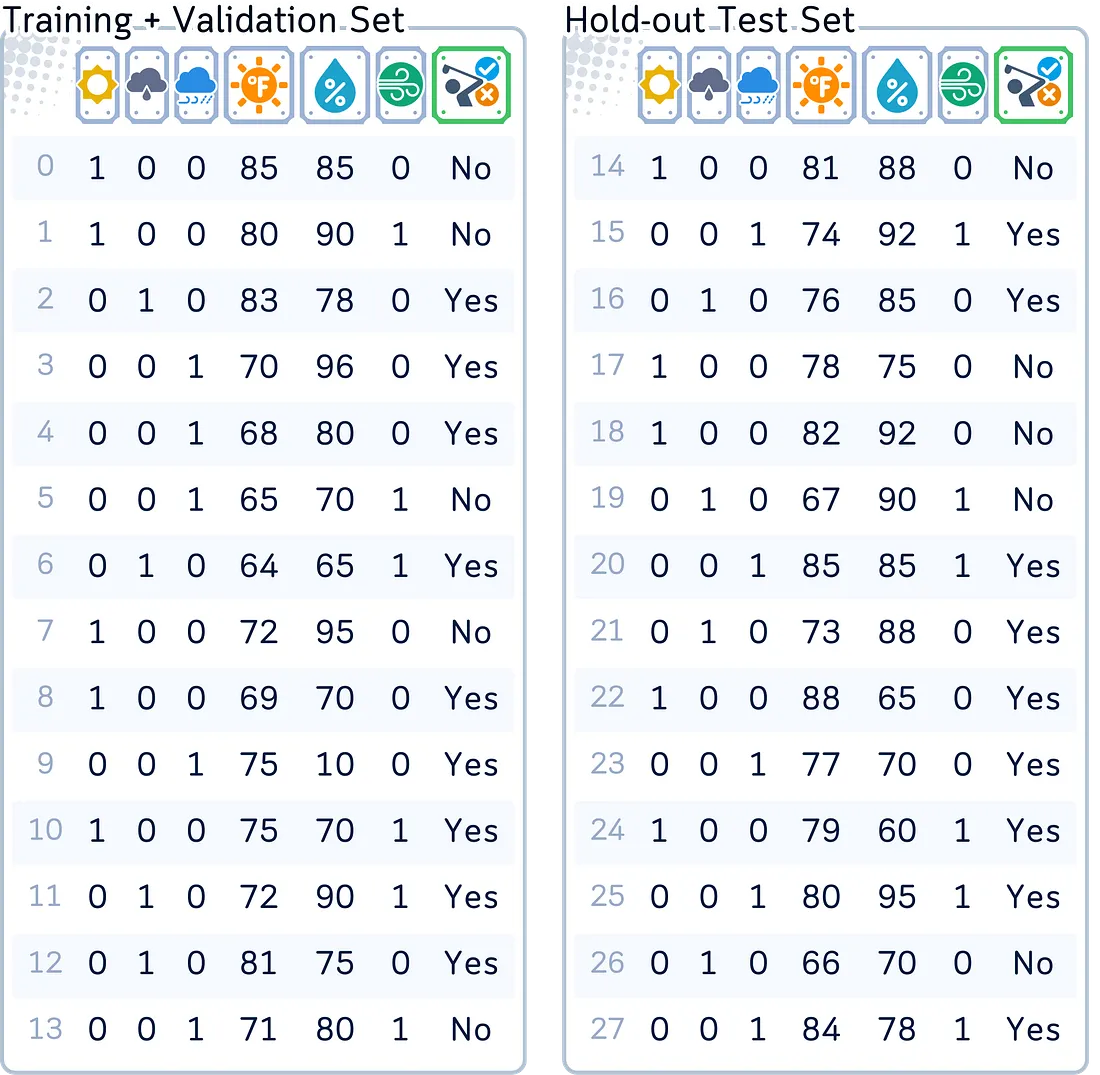
# Pembagian awal train-test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)Di bagian berikutnya, kita akan melihat bagaimana metode cross-validation dapat mengambil 14 hari ini dan membaginya berkali-kali dengan cara yang berbeda. Ini memberi kita gambaran yang lebih baik tentang seberapa baik model kita sebenarnya bekerja, meskipun dengan data yang sangat terbatas.
4 Cross Validation
Cross-validation mengubah cara kita memikirkan pengujian model. Alih-alih menguji model hanya sekali dengan satu pembagian data, kita mengujinya berkali-kali menggunakan pembagian yang berbeda dari data yang sama. Ini membantu kita memahami dengan lebih baik seberapa baik model kita sebenarnya bekerja.
Ide utama cross-validation adalah menguji model beberapa kali, dan setiap kali dataset pelatihan dan pengujian berasal dari bagian data yang berbeda. Ini membantu mencegah bias dari satu pembagian data yang kebetulan sangat bagus (atau sangat buruk).
Mengapa ini penting? Misalkan model kita mendapat akurasi 95% saat diuji dengan satu cara, tetapi hanya 75% saat diuji dengan cara lain menggunakan data yang sama. Angka mana yang benar-benar menunjukkan kualitas model kita? Cross-validation membantu menjawab pertanyaan ini dengan memberikan banyak hasil pengujian, bukan hanya satu.
4.1 Metode K-Fold
4.1.1 Basic K-Fold Cross-Validation
K-fold cross-validation mengatasi masalah besar dari pembagian sederhana: terlalu bergantung pada satu cara pembagian data. Alih-alih membagi data sekali, K-fold membagi data menjadi K bagian yang sama. Kemudian menguji model beberapa kali, menggunakan bagian yang berbeda untuk pengujian setiap kalinya, sementara semua bagian lainnya digunakan untuk pelatihan.
Angka yang kita pilih untuk K mengubah cara kita menguji model. Kebanyakan orang menggunakan 5 atau 10 untuk K, tetapi ini bisa berubah berdasarkan jumlah data dan kebutuhan proyek. Misalnya dengan K = 3, data dibagi menjadi tiga bagian yang sama. Kita kemudian melatih dan menguji model tiga kali. Setiap kali, 2/3 data digunakan untuk pelatihan dan 1/3 untuk pengujian, tetapi kita merotasi bagian mana yang digunakan untuk pengujian. Dengan cara ini, setiap data digunakan untuk pelatihan maupun pengujian.
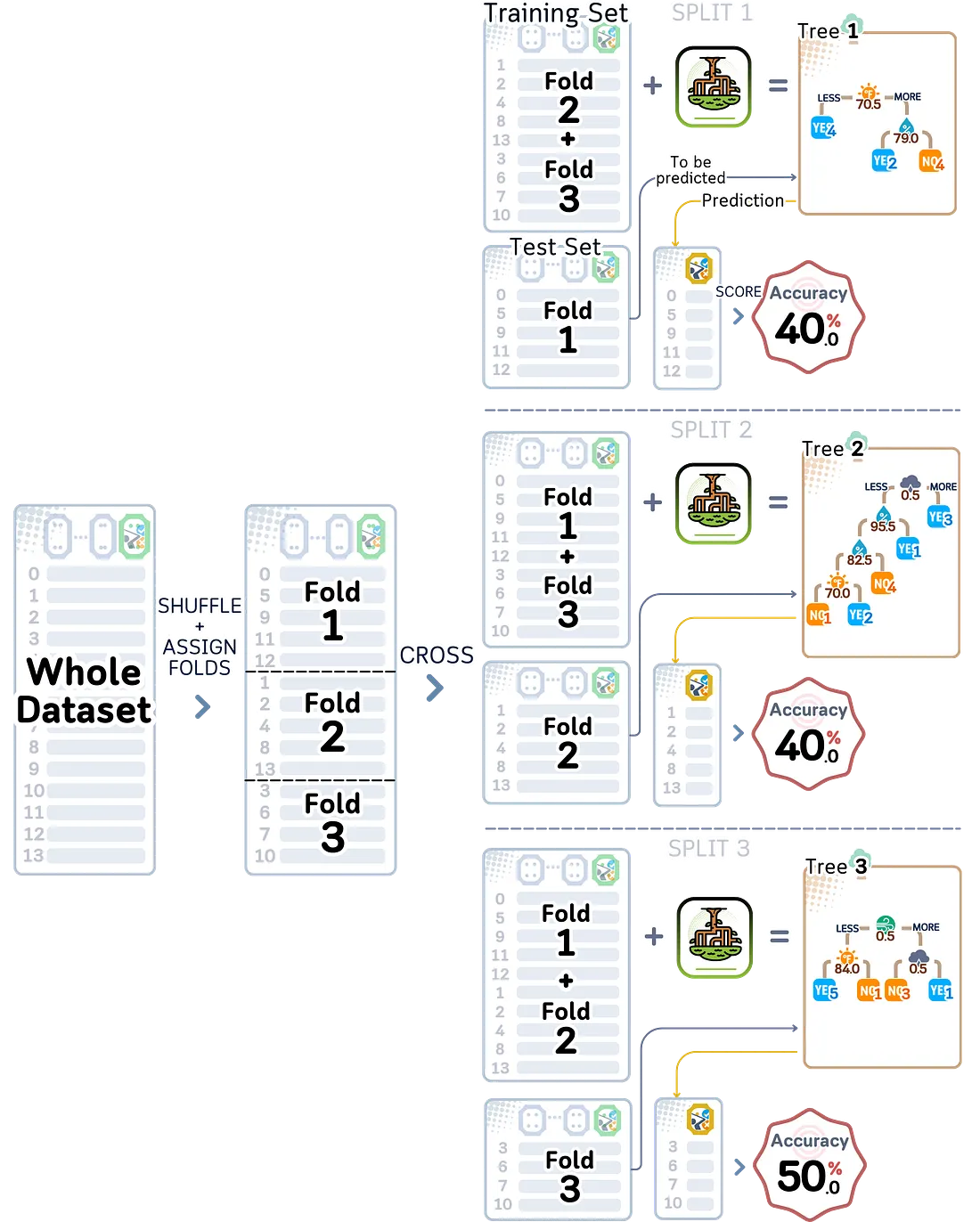
from sklearn.model_selection import KFold, cross_val_score
# Strategi cross-validation
cv = KFold(n_splits=3, shuffle=True, random_state=42)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
# Plot pohon untuk setiap pembagian
fig, axes = plt.subplots(cv.get_n_splits(X_train), 1,
figsize=(4, 3.5*cv.get_n_splits(X_train)), dpi=100)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
ax = axes[i] if cv.get_n_splits(X_train) > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {i+1} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.433 ± 0.047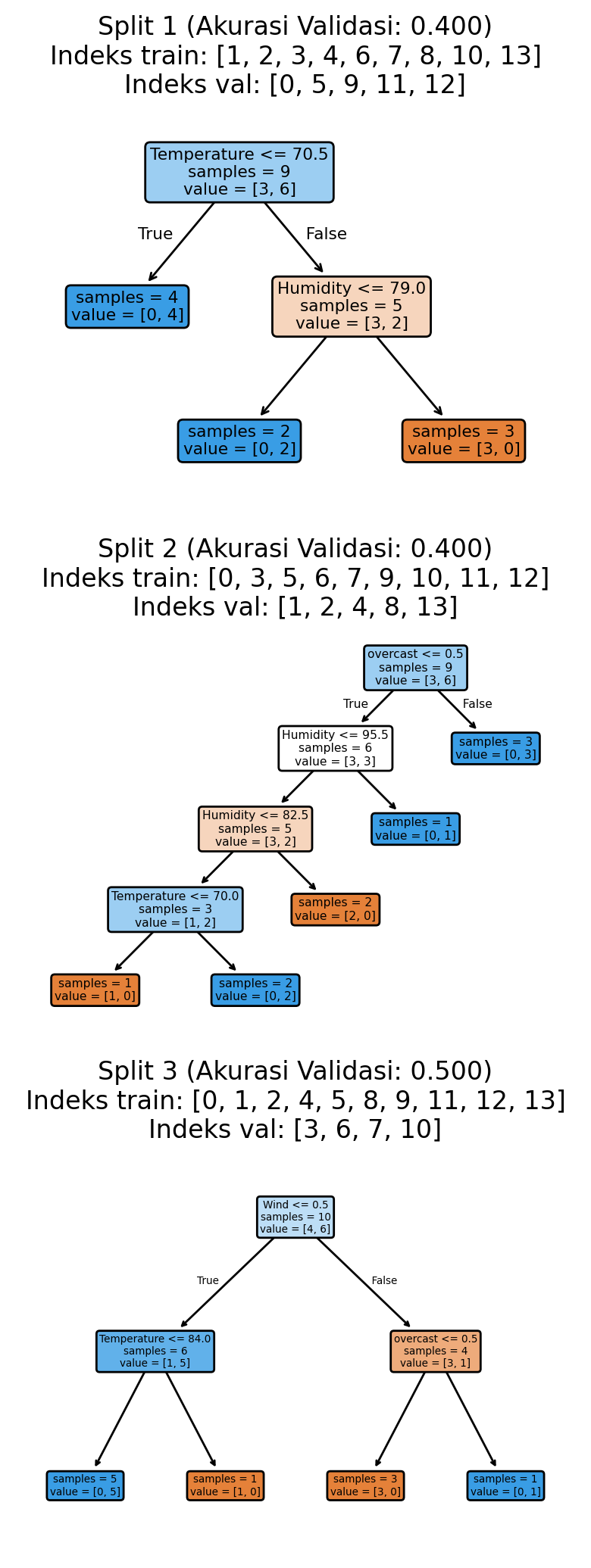
Setelah semua putaran selesai, kita menghitung rata-rata performa dari semua K pengujian. Rata-rata ini memberi kita ukuran yang lebih dapat dipercaya tentang seberapa baik model kita bekerja. Kita juga dapat mempelajari kestabilan model dengan melihat seberapa banyak hasil berubah antara putaran pengujian yang berbeda.
4.1.2 Stratified K-Fold
K-fold dasar biasanya bekerja dengan baik, tetapi bisa mengalami masalah ketika data kita tidak seimbang — artinya kita memiliki jauh lebih banyak dari satu jenis daripada yang lain. Misalnya, jika kita memiliki 100 titik data dan 90 di antaranya adalah tipe A sementara hanya 10 adalah tipe B, membagi data ini secara acak mungkin menghasilkan potongan-potongan yang tidak memiliki cukup tipe B untuk diuji dengan benar.
Stratified K-fold memperbaiki ini dengan memastikan setiap pembagian memiliki campuran yang sama seperti data asli kita. Jika dataset lengkap kita memiliki 10% tipe B, setiap pembagian juga akan memiliki sekitar 10% tipe B. Ini membuat pengujian kita lebih andal, terutama ketika beberapa jenis data jauh lebih jarang dari yang lain.
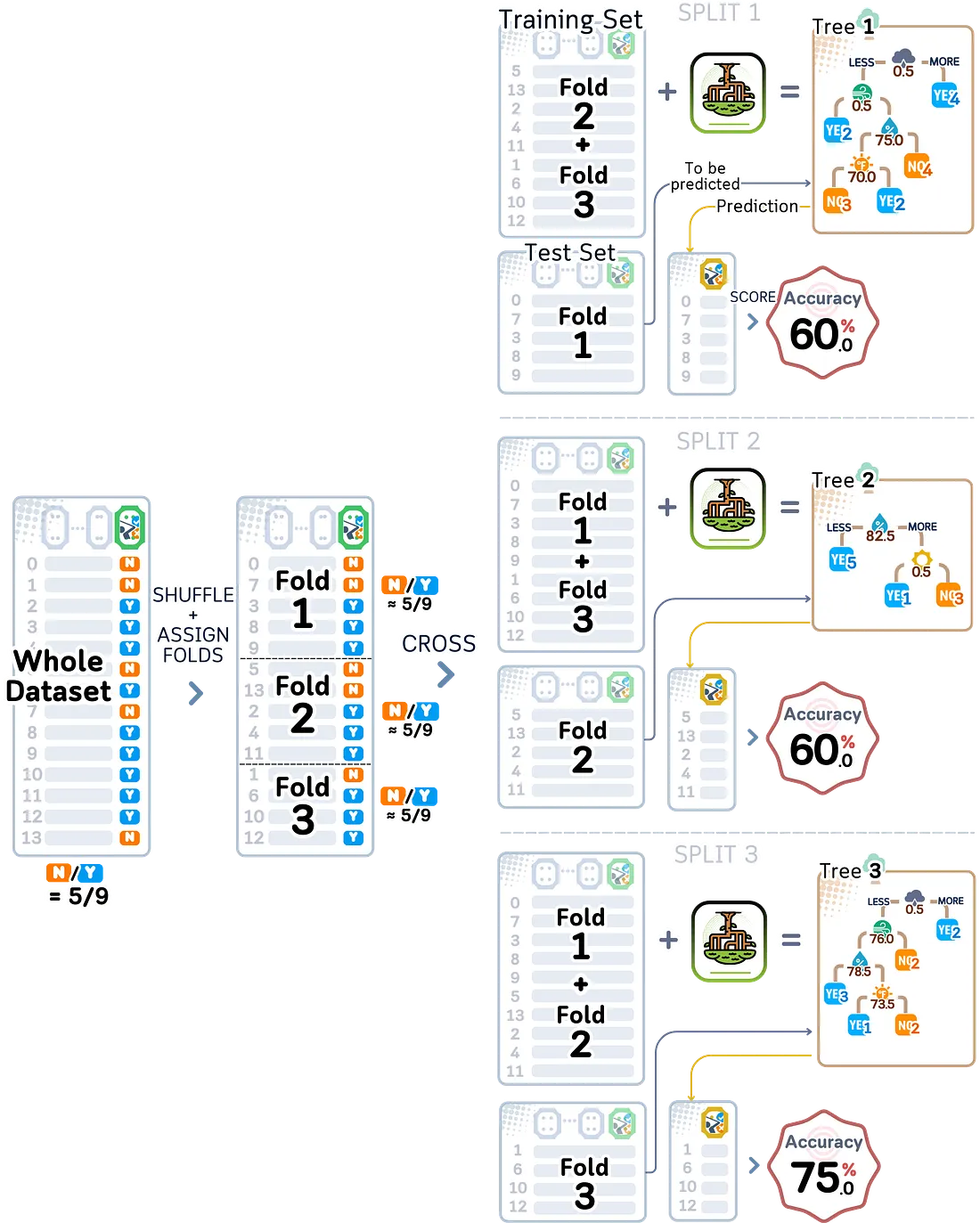
from sklearn.model_selection import StratifiedKFold
# Strategi cross-validation
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
# Plot pohon
fig, axes = plt.subplots(cv.get_n_splits(X_train), 1,
figsize=(5, 4*cv.get_n_splits(X_train)), dpi=100)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
ax = axes[i] if cv.get_n_splits(X_train) > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {i+1} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.650 ± 0.071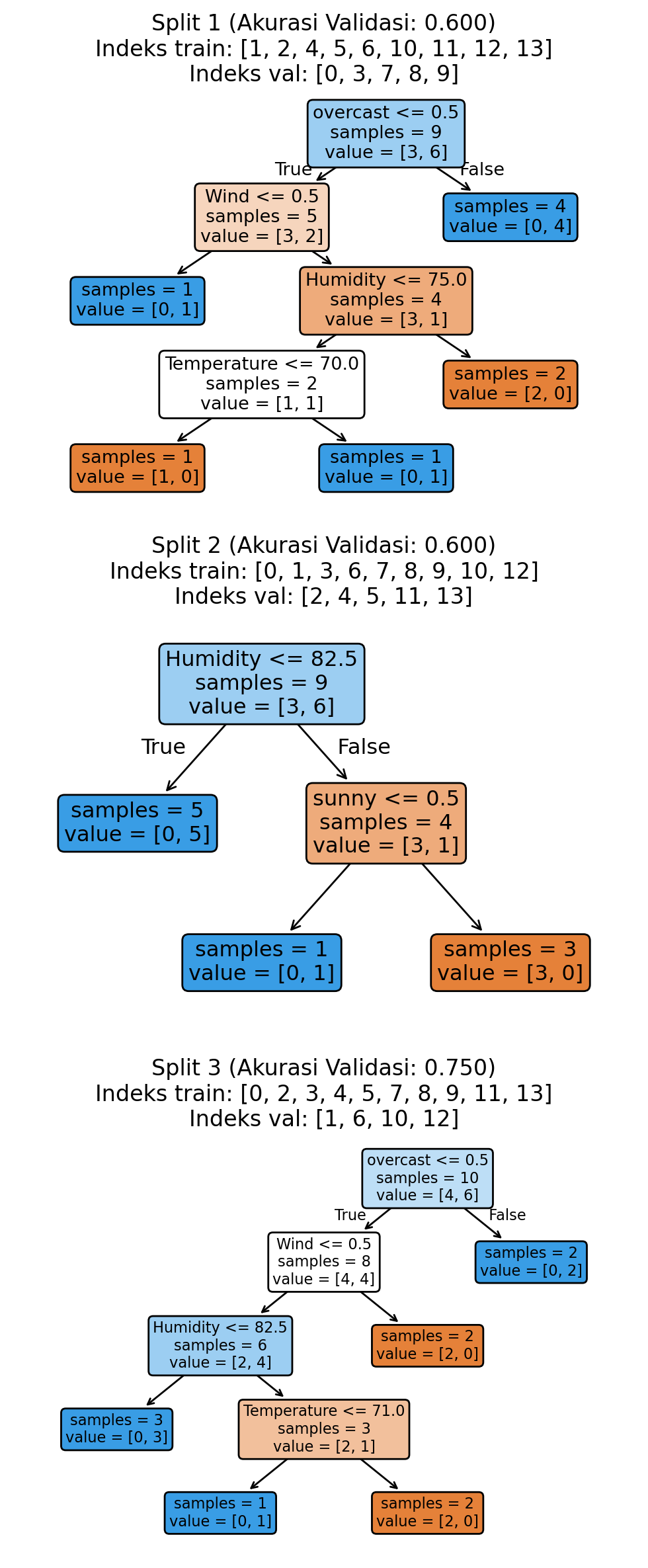
Menjaga keseimbangan ini membantu dalam dua cara. Pertama, memastikan setiap pembagian benar-benar mewakili data kita. Kedua, memberikan hasil pengujian yang lebih konsisten. Artinya jika kita menguji model berkali-kali, kita kemungkinan akan mendapatkan hasil yang serupa setiap kalinya.
4.1.3 Repeated K-Fold
Terkadang, bahkan ketika menggunakan K-fold validasi, hasil pengujian kita bisa berubah banyak antara pembagian acak yang berbeda. Repeated K-fold mengatasi ini dengan menjalankan seluruh proses K-fold beberapa kali, menggunakan pembagian acak yang berbeda setiap kalinya.
Misalnya, jika kita menjalankan 5-fold cross-validation tiga kali, model kita akan melalui pelatihan dan pengujian sebanyak 15 kali. Dengan pengujian sebanyak ini, kita dapat lebih baik membedakan mana perbedaan hasil yang berasal dari kebetulan acak dan mana yang menunjukkan seberapa baik performa model kita yang sebenarnya. Kelemahannya adalah semua pengujian tambahan ini membutuhkan lebih banyak waktu.
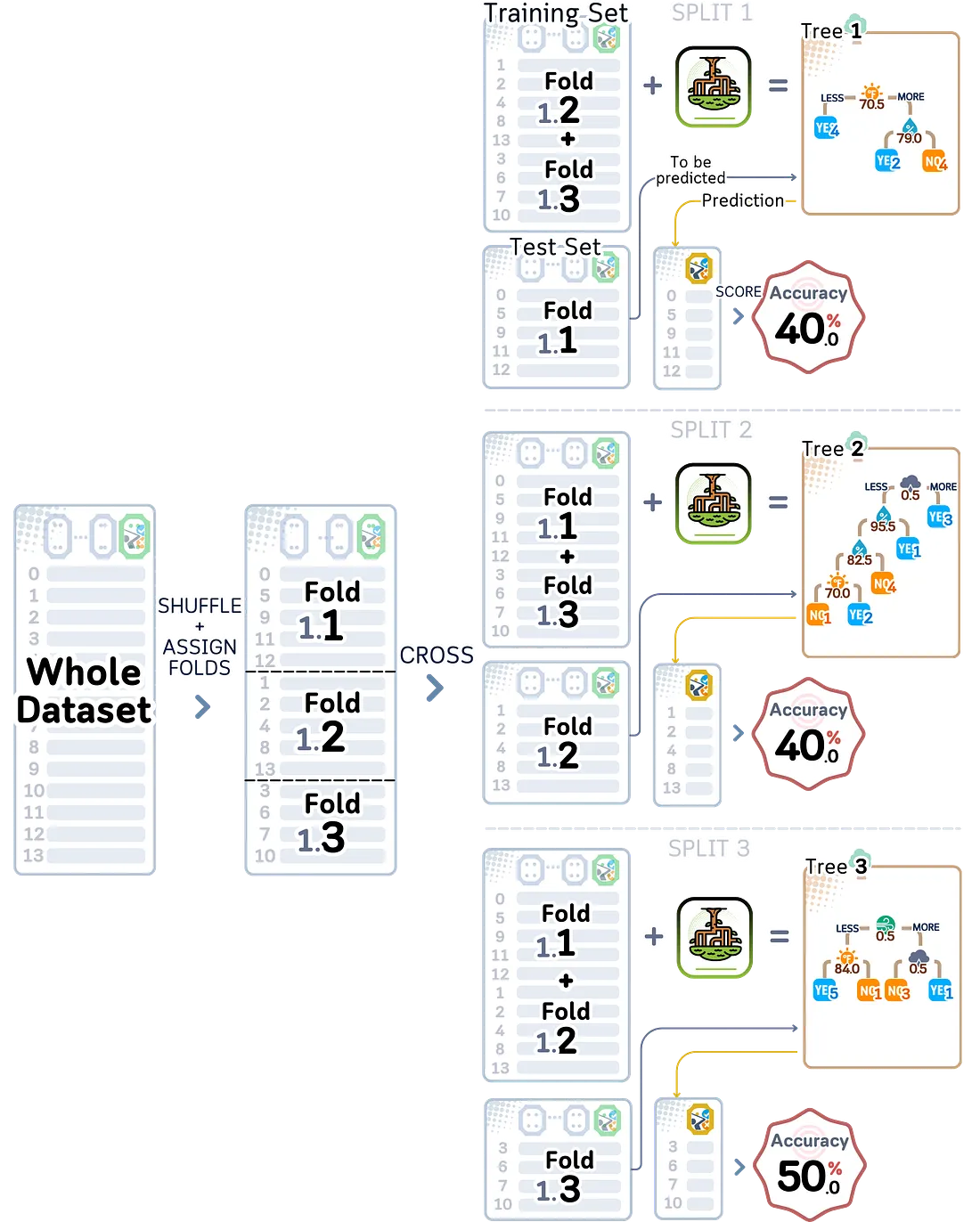
from sklearn.model_selection import RepeatedKFold
# Strategi cross-validation
n_splits = 3
cv = RepeatedKFold(n_splits=n_splits, n_repeats=2, random_state=42)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
# Plot sebagian pohon
total_splits = cv.get_n_splits(X_train) # Akan menjadi 6 (3 fold × 2 pengulangan)
fig, axes = plt.subplots(total_splits, 1, figsize=(5, 4*total_splits), dpi=80)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
repetition, fold = i // n_splits + 1, i % n_splits + 1
ax = axes[i] if total_splits > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {repetition}.{fold} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.425 ± 0.107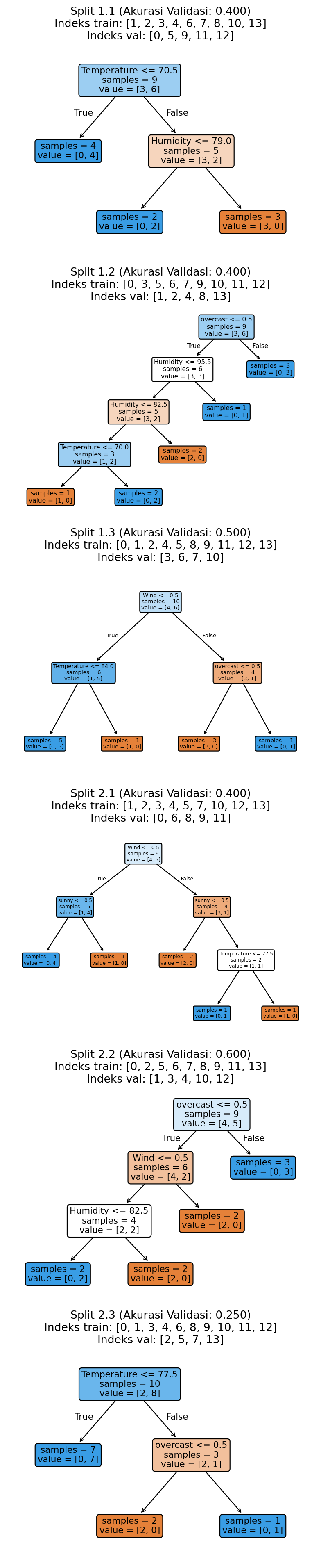
Saat melihat hasil repeated K-fold, karena kita memiliki banyak set hasil pengujian, kita bisa melakukan lebih dari sekadar menghitung rata-rata — kita juga bisa menghitung tingkat kepercayaan terhadap hasil kita. Ini memberi kita pemahaman yang lebih baik tentang seberapa andal model kita.
4.1.4 Repeated Stratified K-Fold
Metode ini menggabungkan dua hal yang baru saja dipelajari: menjaga keseimbangan kelas (stratifikasi) dan menjalankan beberapa putaran pengujian (pengulangan). Metode ini menjaga campuran yang tepat dari berbagai jenis data sambil menguji berkali-kali. Ini bekerja sangat baik ketika kita memiliki dataset kecil yang tidak seimbang — di mana kita memiliki jauh lebih banyak satu jenis data daripada yang lain.
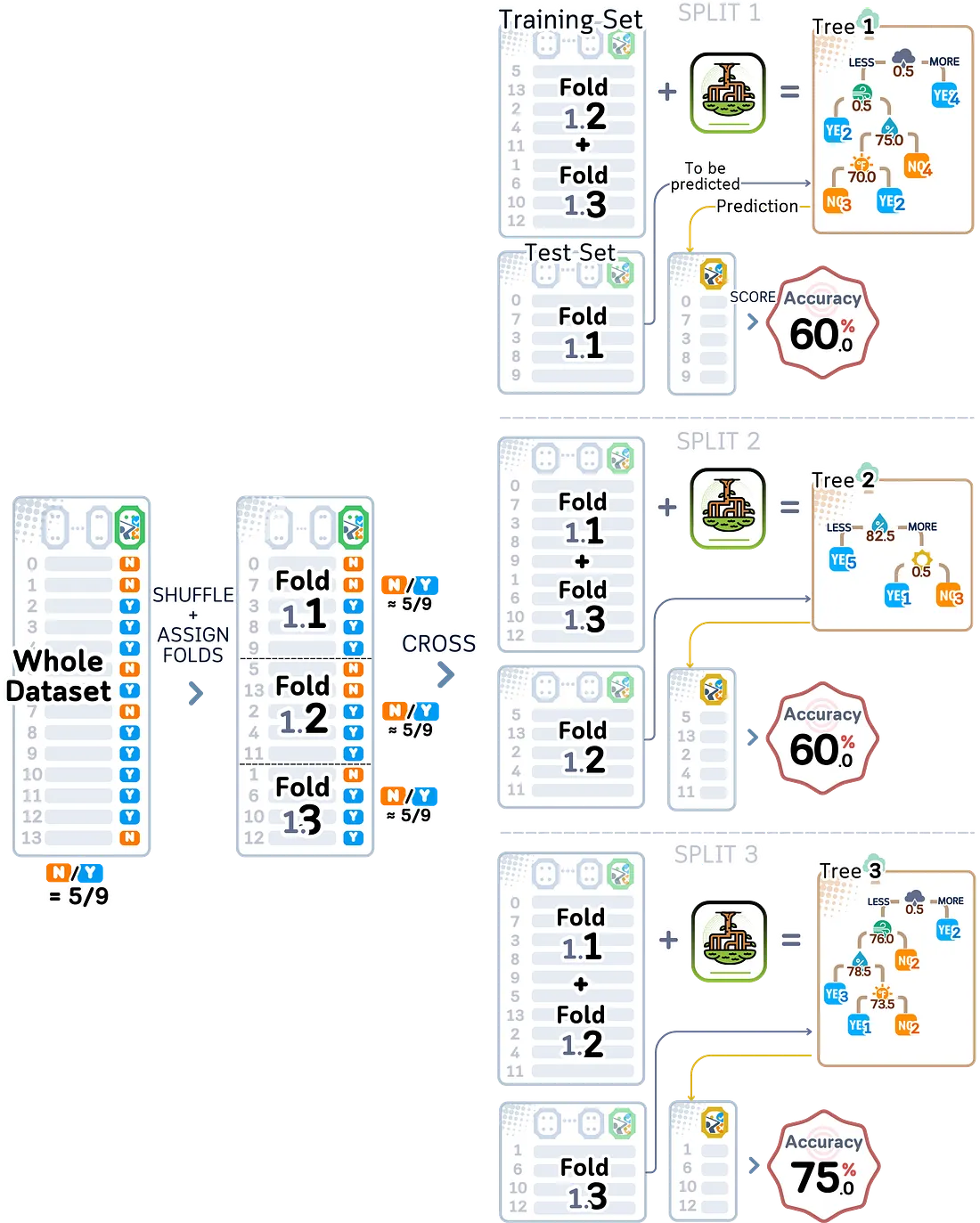
from sklearn.model_selection import RepeatedStratifiedKFold
# Strategi cross-validation
n_splits = 3
cv = RepeatedStratifiedKFold(n_splits=n_splits, n_repeats=2, random_state=42)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
total_splits = cv.get_n_splits(X_train)
fig, axes = plt.subplots(total_splits, 1, figsize=(5, 4*total_splits), dpi=80)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
repetition, fold = i // n_splits + 1, i % n_splits + 1
ax = axes[i] if total_splits > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {repetition}.{fold} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.475 ± 0.238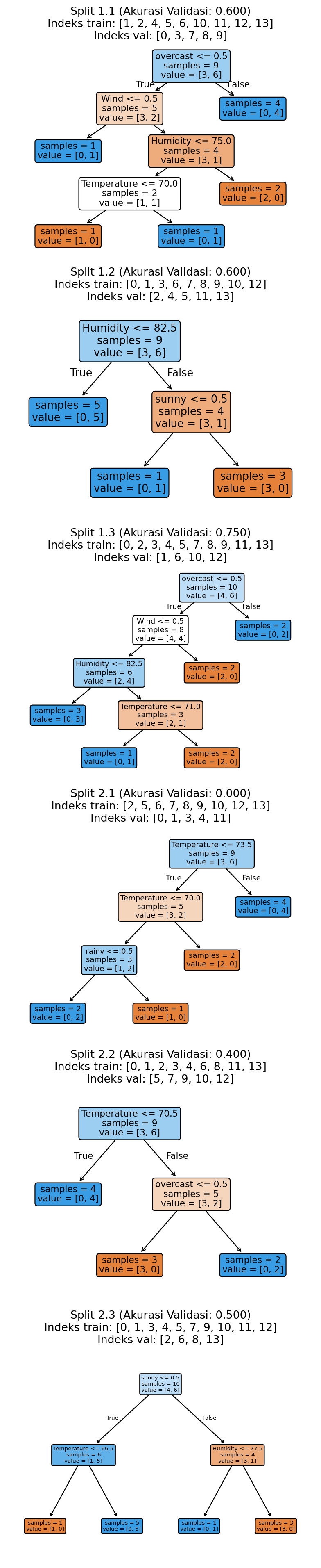
Namun ada pertimbangan waktu: metode ini membutuhkan lebih banyak waktu komputasi. Setiap kali kita mengulangi seluruh proses, waktu pelatihan model berlipat ganda. Saat memutuskan apakah akan menggunakan metode ini, kita perlu mempertimbangkan apakah mendapatkan hasil yang lebih andal sepadan dengan waktu ekstra yang dibutuhkan.
4.1.5 Group K-Fold
Terkadang data kita secara alami datang dalam kelompok-kelompok yang harus tetap bersama. Bayangkan data golf di mana kita memiliki banyak pengukuran dari lapangan golf yang sama sepanjang tahun. Jika kita meletakkan beberapa pengukuran dari satu lapangan golf di data pelatihan dan yang lainnya di data pengujian, kita menciptakan masalah: model kita secara tidak langsung akan mempelajari data pengujian selama pelatihan karena telah melihat pengukuran lain dari lapangan yang sama.
Group K-fold memperbaiki ini dengan menjaga semua data dari kelompok yang sama (seperti semua pengukuran dari satu lapangan golf) bersama dalam bagian yang sama saat kita membagi data. Ini mencegah model secara tidak sengaja melihat informasi yang tidak seharusnya, yang bisa membuat kita berpikir performanya lebih baik dari yang sebenarnya.
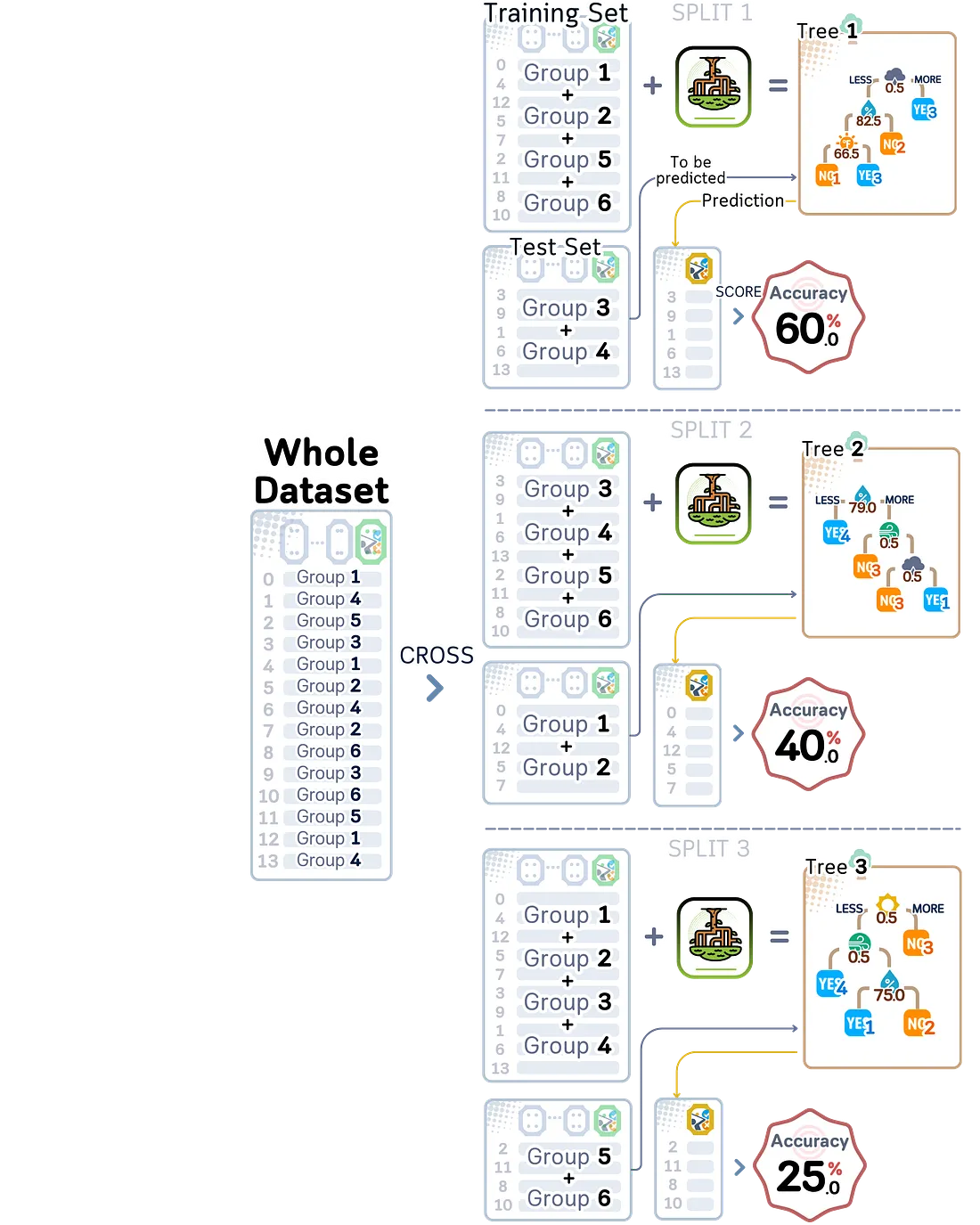
from sklearn.model_selection import GroupKFold
# Buat kelompok
groups = ['Group 1', 'Group 4', 'Group 5', 'Group 3', 'Group 1', 'Group 2', 'Group 4',
'Group 2', 'Group 6', 'Group 3', 'Group 6', 'Group 5', 'Group 1', 'Group 4',
'Group 4', 'Group 3', 'Group 1', 'Group 5', 'Group 6', 'Group 2', 'Group 4',
'Group 5', 'Group 1', 'Group 4', 'Group 5', 'Group 5', 'Group 2', 'Group 6']
# Train-Test Split sederhana
X_train_g, X_test_g, y_train_g, y_test_g, groups_train, groups_test = train_test_split(
X, y, groups, test_size=0.5, shuffle=False
)
# Strategi cross-validation
cv = GroupKFold(n_splits=3)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train_g, y_train_g,
cv=cv.split(X_train_g, y_train_g, groups=groups_train))
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
fig, axes = plt.subplots(cv.get_n_splits(X_train_g), 1,
figsize=(4, 3.5*cv.get_n_splits(X_train_g)), dpi=100)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train_g, y_train_g, groups=groups_train)):
train_groups = sorted(set(np.array(groups_train)[train_idx]))
val_groups = sorted(set(np.array(groups_train)[val_idx]))
dt.fit(X_train_g.iloc[train_idx], y_train_g.iloc[train_idx])
ax = axes[i] if cv.get_n_splits(X_train_g) > 1 else axes
plot_tree(dt, feature_names=X_train_g.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {i+1} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)} ({", ".join(train_groups)})\n'
f'Indeks val: {list(val_idx)} ({", ".join(val_groups)})')
plt.tight_layout()
plt.show()Akurasi validasi: 0.417 ± 0.143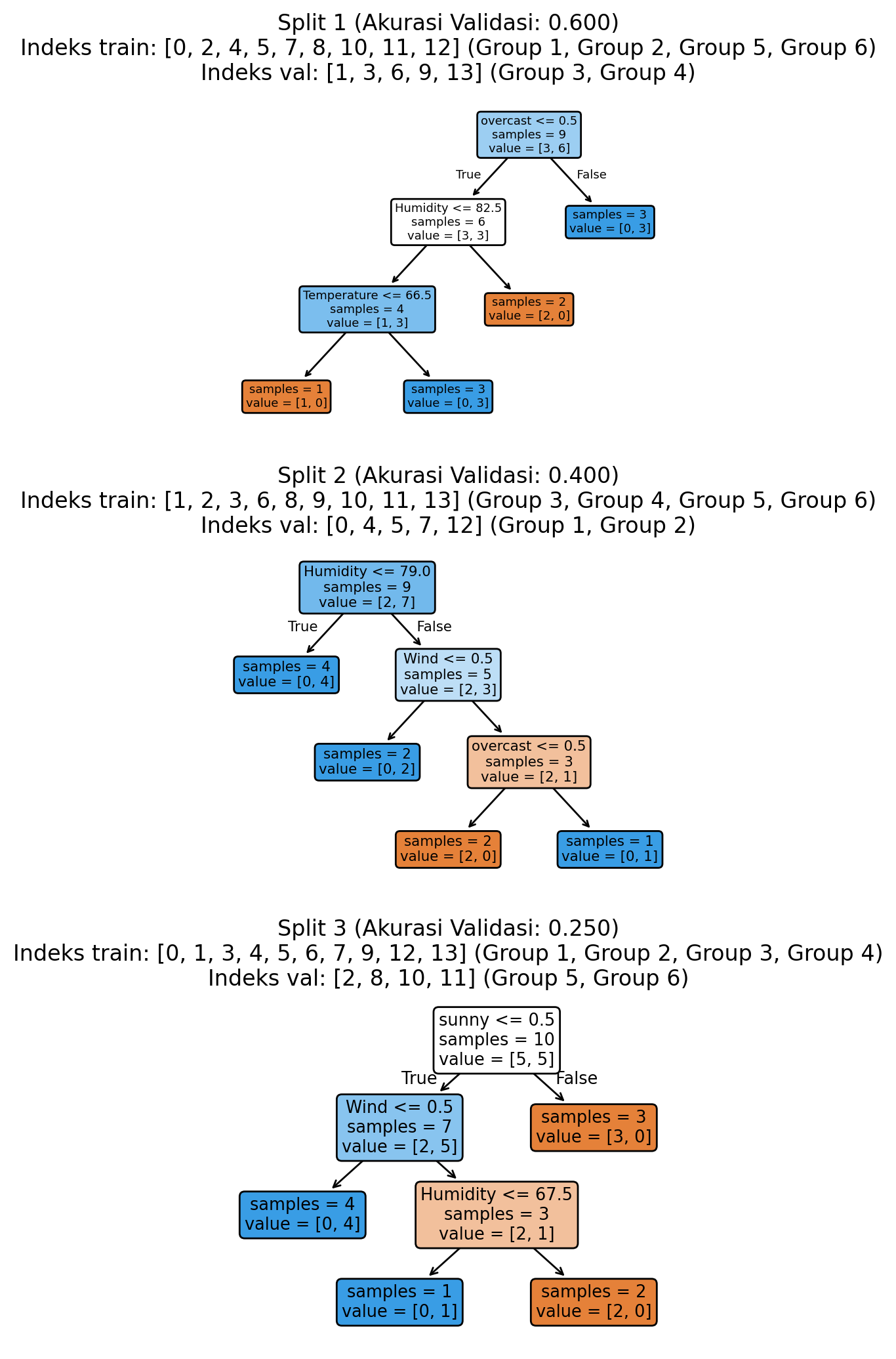
Metode ini bisa sangat penting saat bekerja dengan data yang secara alami datang dalam kelompok, seperti beberapa pembacaan cuaca dari lapangan golf yang sama atau data yang dikumpulkan dari waktu ke waktu dari lokasi yang sama.
4.1.6 Time Series Split
Ketika kita membagi data secara acak dalam K-fold biasa, kita mengasumsikan setiap data tidak memengaruhi yang lain. Namun ini tidak cocok untuk data yang berubah seiring waktu, di mana apa yang terjadi sebelumnya memengaruhi apa yang terjadi berikutnya. Time series split mengubah K-fold agar bekerja lebih baik dengan data yang terurut berdasarkan waktu.
Alih-alih membagi data secara acak, time series split menggunakan data secara berurutan, dari masa lalu ke masa depan. Data pelatihan hanya mencakup informasi dari waktu sebelum data pengujian. Ini sesuai dengan cara kita menggunakan model di dunia nyata, di mana kita menggunakan data masa lalu untuk memprediksi apa yang akan terjadi selanjutnya.
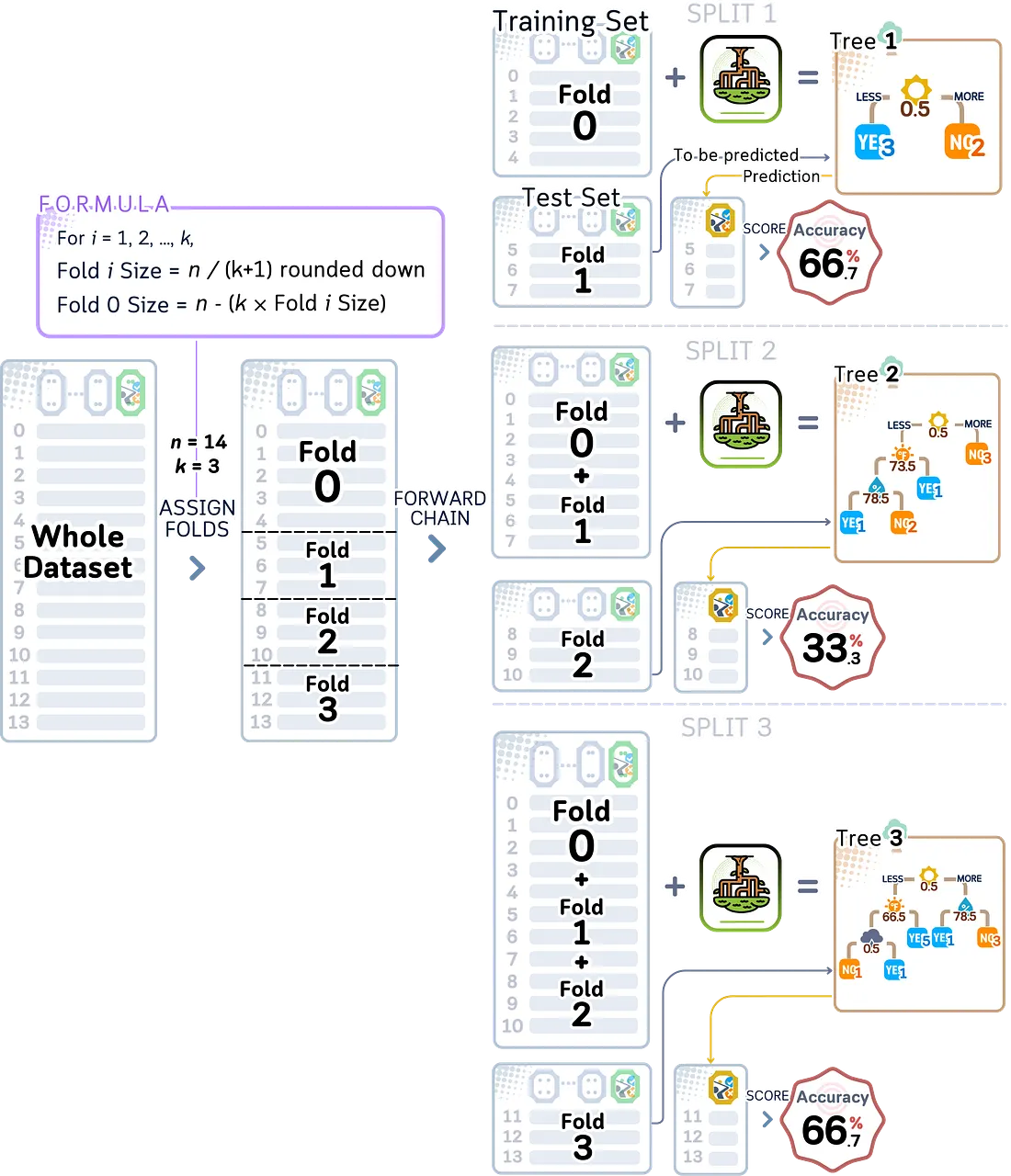
from sklearn.model_selection import TimeSeriesSplit
# Strategi cross-validation
cv = TimeSeriesSplit(n_splits=3)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
fig, axes = plt.subplots(cv.get_n_splits(X_train), 1,
figsize=(4, 3.5*cv.get_n_splits(X_train)), dpi=100)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
ax = axes[i] if cv.get_n_splits(X_train) > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {i+1} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.556 ± 0.157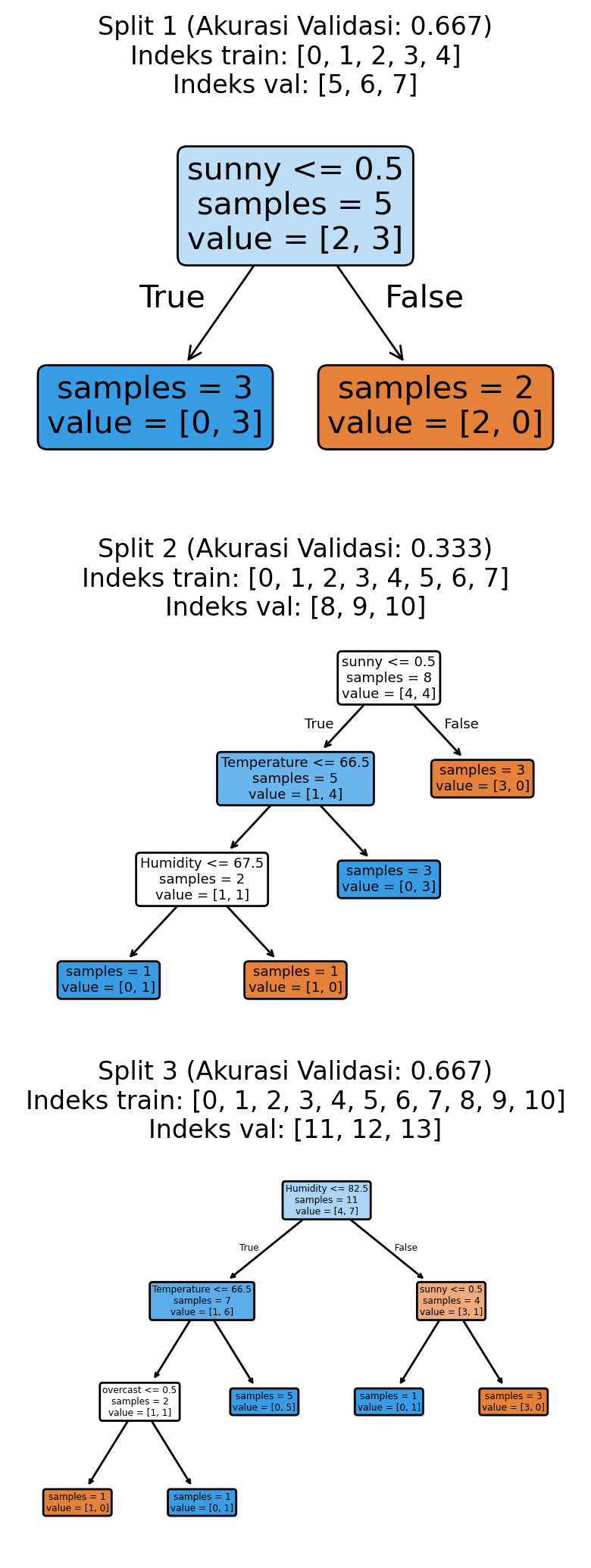
Misalnya, dengan K=3 dan data golf kita, kita mungkin melatih menggunakan data cuaca dari Januari dan Februari untuk memprediksi pola bermain golf di Maret. Kemudian melatih menggunakan Januari hingga Maret untuk memprediksi April, dan seterusnya. Dengan hanya maju ke depan dalam waktu, metode ini memberi kita gambaran yang lebih realistis tentang seberapa baik model kita akan bekerja saat memprediksi pola bermain golf di masa depan.
4.2 Metode Leave-Out
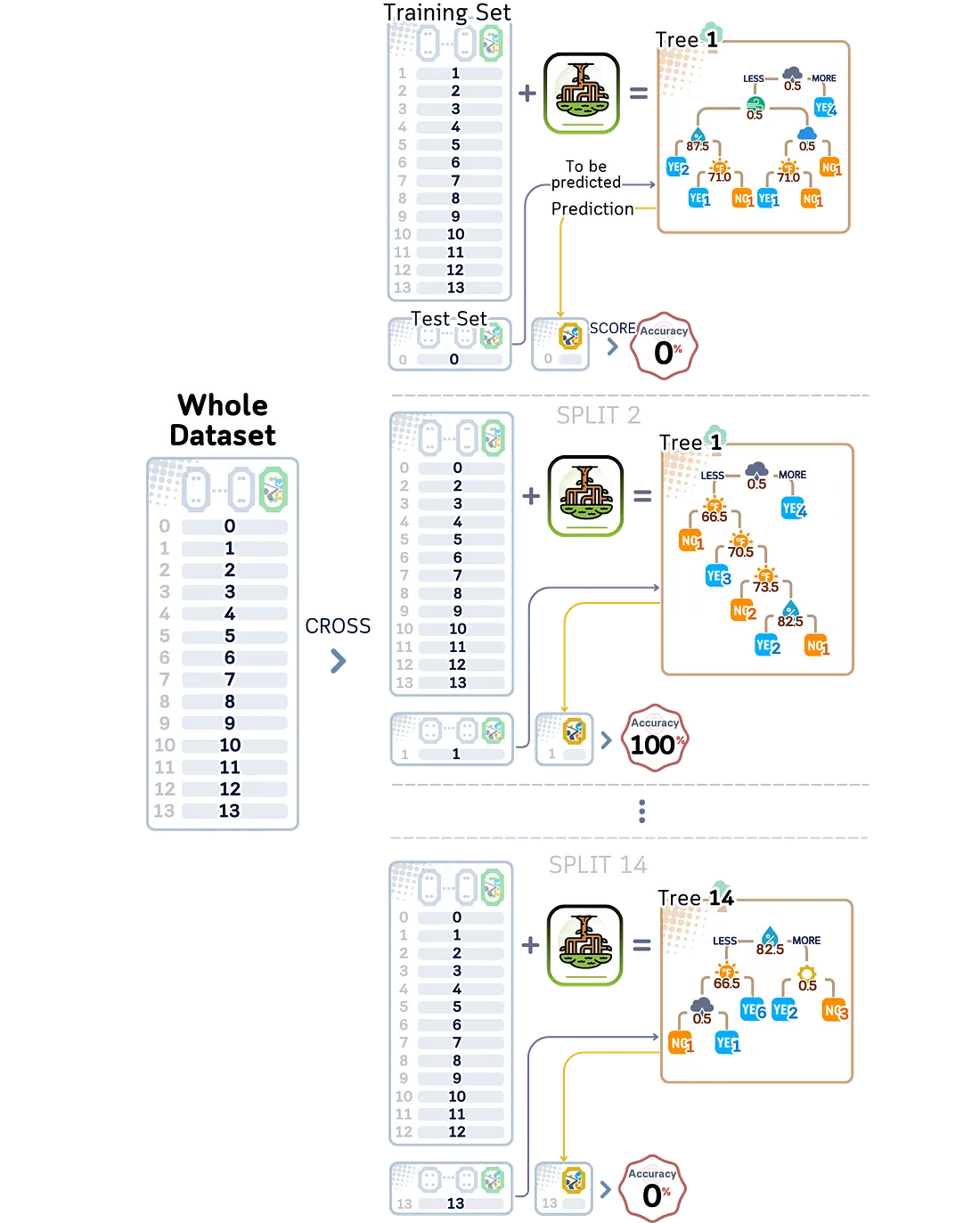
4.2.1 Leave-One-Out Cross-Validation (LOOCV)
Leave-One-Out Cross-Validation (LOOCV) adalah metode validasi yang paling menyeluruh. Metode ini hanya menggunakan satu sampel untuk pengujian dan semua sampel lainnya untuk pelatihan. Validasi diulang hingga setiap data telah digunakan untuk pengujian.
Misalkan kita memiliki 100 hari data cuaca golf. LOOCV akan melatih dan menguji model 100 kali. Setiap kali, ia menggunakan 99 hari untuk pelatihan dan 1 hari untuk pengujian. Metode ini menghilangkan semua keacakan dalam pengujian — jika kita menjalankan LOOCV pada data yang sama beberapa kali, kita akan selalu mendapatkan hasil yang sama.
Namun LOOCV membutuhkan banyak waktu komputasi. Jika kita memiliki N data, kita perlu melatih model sebanyak N kali. Dengan dataset besar atau model yang kompleks, ini mungkin terlalu lama untuk praktis.
from sklearn.model_selection import LeaveOneOut
# Strategi cross-validation
cv = LeaveOneOut()
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}") Akurasi validasi: 0.429 ± 0.495LOOCV bekerja sangat baik ketika kita tidak memiliki banyak data dan perlu memanfaatkan setiap data semaksimal mungkin. Karena hasilnya bergantung pada setiap data tunggal, hasilnya bisa sangat bervariasi jika data kita memiliki kebisingan atau nilai yang tidak biasa.
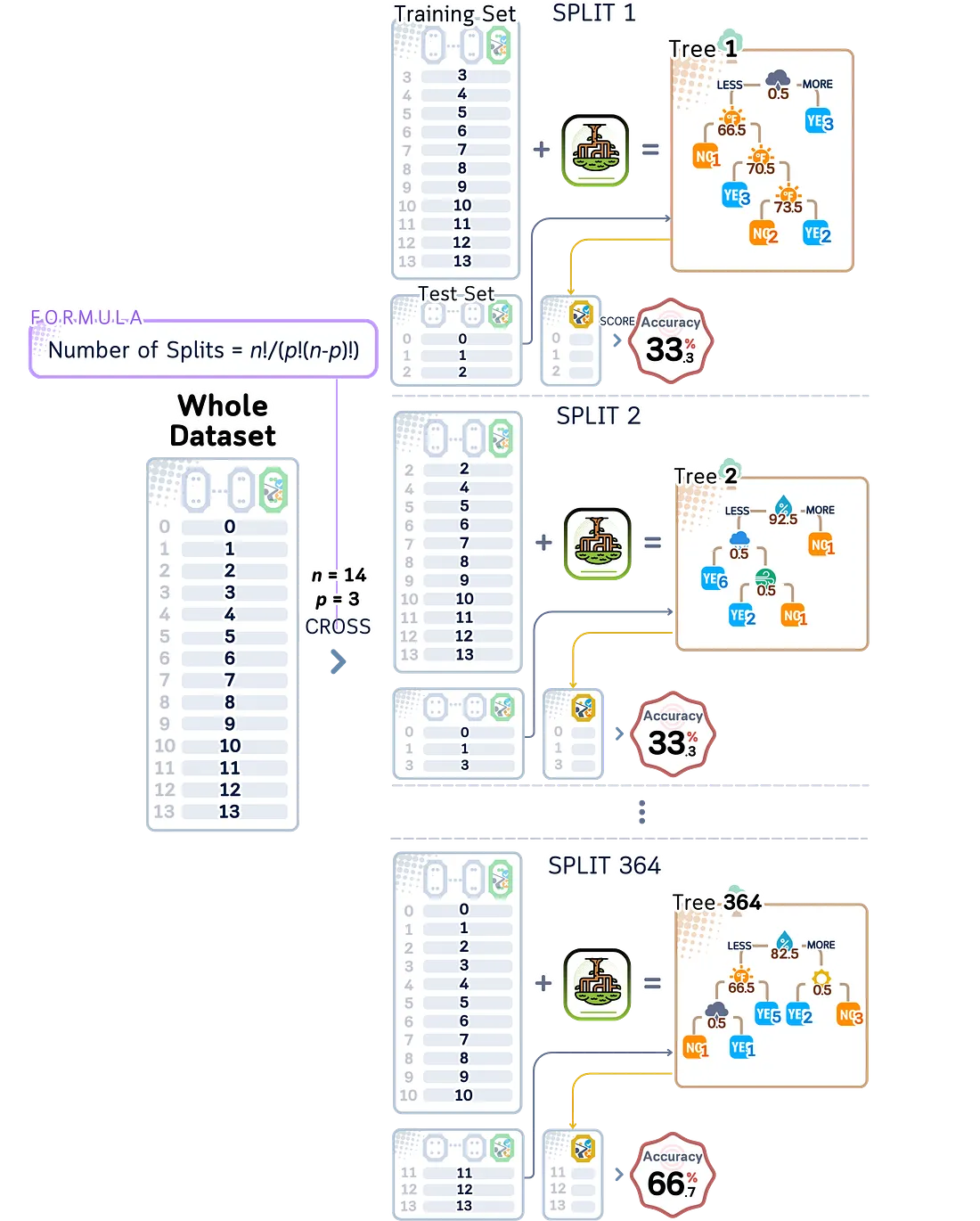
4.2.2 Leave-P-Out Cross-Validation
Leave-P-Out membangun ide dari Leave-One-Out, tetapi alih-alih menguji dengan hanya satu data, ia menguji dengan P data sekaligus. Ini menciptakan keseimbangan antara Leave-One-Out dan K-fold validasi. Angka yang kita pilih untuk P mengubah cara kita menguji model dan berapa lama waktu yang dibutuhkan.
Masalah utama Leave-P-Out adalah betapa cepatnya jumlah kemungkinan kombinasi pengujian bertambah. Misalnya, jika kita memiliki 100 hari data cuaca golf dan ingin menguji dengan 5 hari sekaligus (P=5), ada jutaan cara berbeda untuk memilih 5 hari tersebut. Menguji semua kombinasi ini membutuhkan terlalu banyak waktu ketika kita memiliki banyak data atau menggunakan angka yang lebih besar untuk P.
from sklearn.model_selection import LeavePOut
# Strategi cross-validation
cv = LeavePOut(p=3)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}") Akurasi validasi: 0.441 ± 0.254Karena keterbatasan praktis ini, Leave-P-Out sebagian besar digunakan dalam kasus khusus di mana kita memerlukan pengujian yang sangat menyeluruh dan memiliki dataset yang cukup kecil. Metode ini sangat berguna dalam proyek penelitian di mana mendapatkan hasil pengujian yang paling akurat lebih penting daripada berapa lama pengujian berlangsung.
4.3 Metode Acak
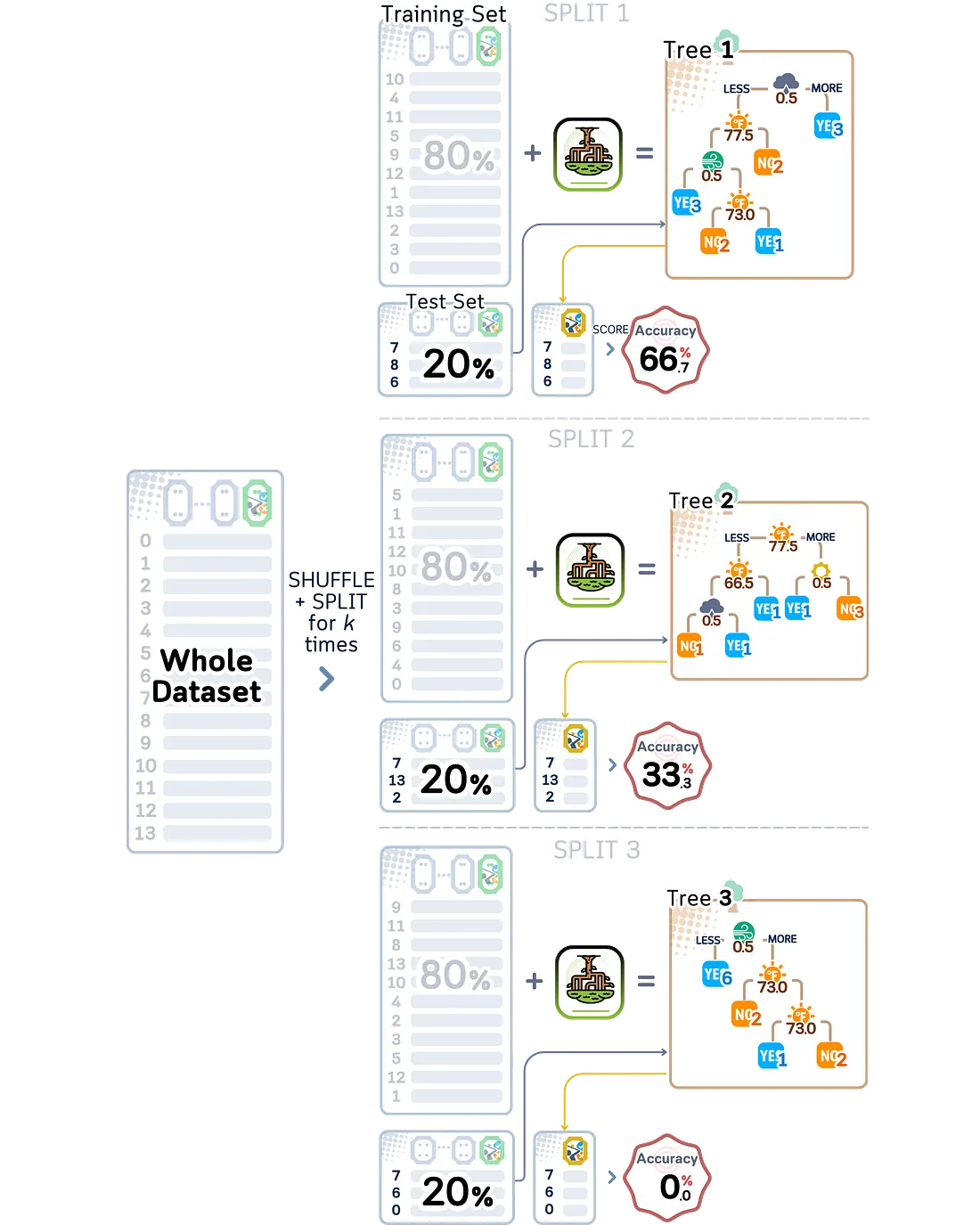
4.3.1 ShuffleSplit Cross-Validation
ShuffleSplit bekerja secara berbeda dari metode validasi lainnya dengan menggunakan pembagian yang sepenuhnya acak. Alih-alih membagi data secara terorganisir seperti K-fold, atau menguji setiap kemungkinan kombinasi seperti Leave-P-Out, ShuffleSplit membuat pembagian pelatihan dan pengujian yang acak setiap kali.
Yang membedakan ShuffleSplit dari K-fold adalah pembagiannya tidak mengikuti pola apa pun. Dalam K-fold, setiap data digunakan tepat satu kali untuk pengujian. Tetapi dalam ShuffleSplit, satu hari data cuaca golf mungkin digunakan untuk pengujian beberapa kali, atau mungkin tidak digunakan untuk pengujian sama sekali. Keacakan ini memberi kita cara yang berbeda untuk memahami seberapa baik performa model kita.
ShuffleSplit bekerja sangat baik dengan dataset besar di mana K-fold mungkin membutuhkan waktu terlalu lama. Kita dapat memilih berapa kali ingin menguji, terlepas dari berapa banyak data yang dimiliki. Kita juga bisa mengontrol seberapa besar setiap pembagian.
from sklearn.model_selection import ShuffleSplit
# Strategi cross-validation
cv = ShuffleSplit(n_splits=3, test_size=0.2, random_state=41)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
fig, axes = plt.subplots(cv.get_n_splits(X_train), 1,
figsize=(4, 3.5*cv.get_n_splits(X_train)), dpi=100)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
ax = axes[i] if cv.get_n_splits(X_train) > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {i+1} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.333 ± 0.272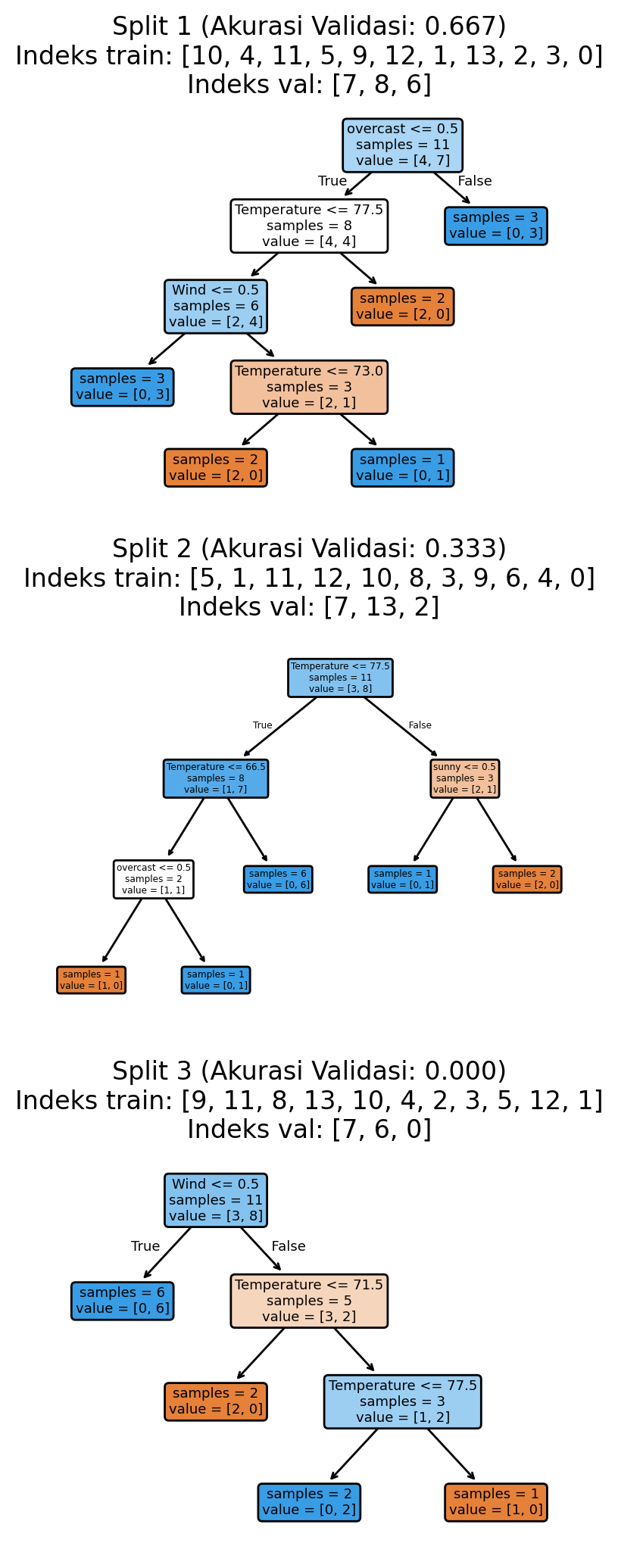
Karena ShuffleSplit dapat membuat sebanyak mungkin pembagian acak yang kita inginkan, metode ini berguna ketika kita ingin melihat bagaimana performa model berubah dengan pembagian acak yang berbeda, atau ketika kita memerlukan lebih banyak pengujian untuk yakin dengan hasilnya.
4.3.2 Stratified ShuffleSplit
Stratified ShuffleSplit menggabungkan pembagian acak dengan menjaga campuran jenis data yang tepat. Seperti Stratified K-fold, metode ini memastikan setiap pembagian memiliki persentase yang kira-kira sama dari setiap jenis data seperti dataset penuh kita.
Metode ini memberi kita yang terbaik dari kedua dunia: kebebasan pembagian acak dan keadilan dalam menjaga data tetap seimbang. Misalnya, jika dataset golf kita memiliki 70% hari “ya” dan 30% hari “tidak” untuk bermain golf, setiap pembagian acak akan mencoba mempertahankan campuran 70-30 yang sama. Ini sangat berguna saat kita memiliki data yang tidak seimbang, di mana pembagian acak mungkin secara tidak sengaja membuat set pengujian yang tidak mewakili data kita dengan baik.
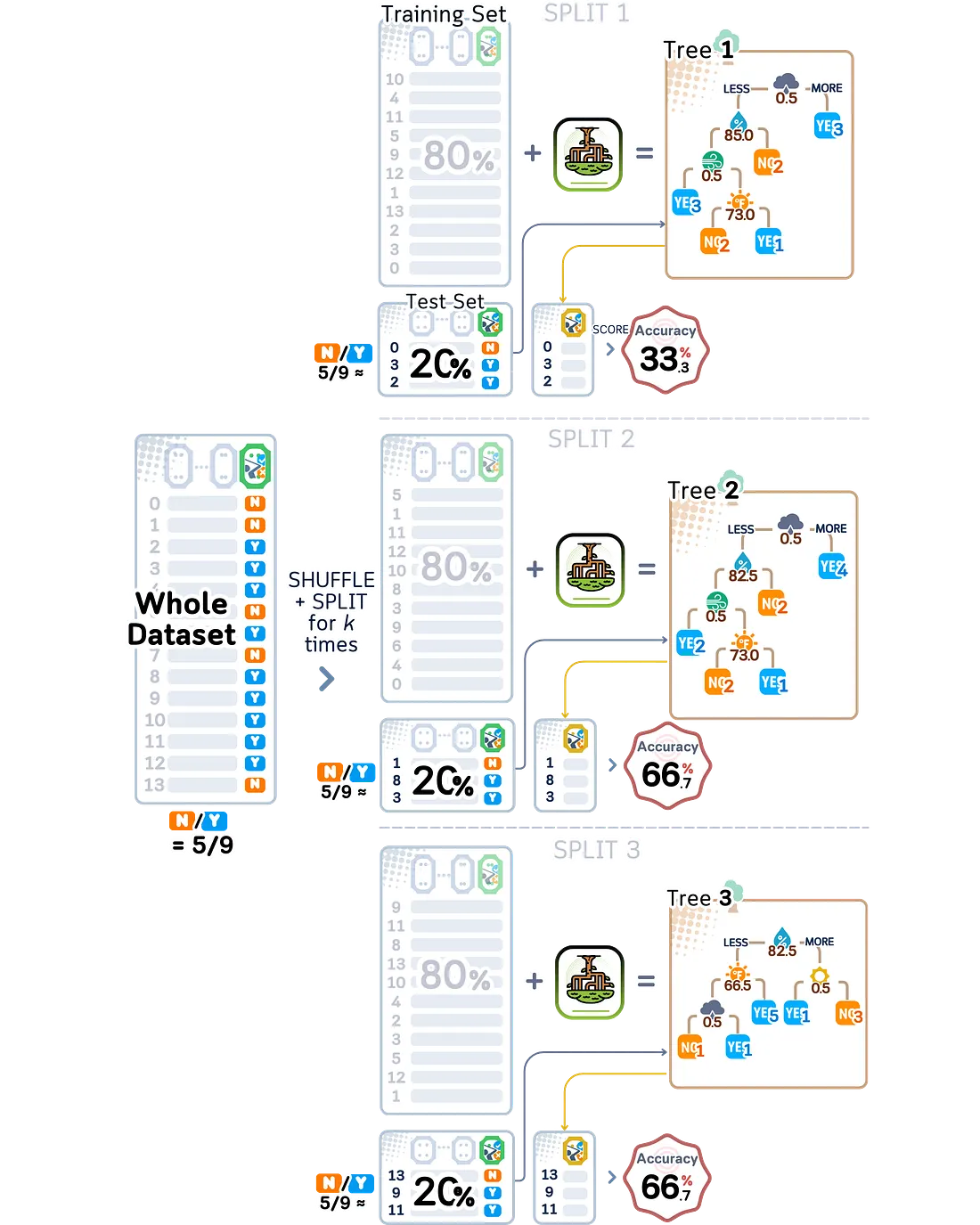
from sklearn.model_selection import StratifiedShuffleSplit
# Strategi cross-validation
cv = StratifiedShuffleSplit(n_splits=3, test_size=0.2, random_state=41)
# Hitung skor cross-validation
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
fig, axes = plt.subplots(cv.get_n_splits(X_train), 1,
figsize=(4, 3.5*cv.get_n_splits(X_train)), dpi=100)
for i, (train_idx, val_idx) in enumerate(cv.split(X_train, y_train)):
dt.fit(X_train.iloc[train_idx], y_train.iloc[train_idx])
ax = axes[i] if cv.get_n_splits(X_train) > 1 else axes
plot_tree(dt, feature_names=X_train.columns, impurity=False,
filled=True, rounded=True, ax=ax)
ax.set_title(f'Split {i+1} (Akurasi Validasi: {scores[i]:.3f})\n'
f'Indeks train: {list(train_idx)}\nIndeks val: {list(val_idx)}')
plt.tight_layout()
plt.show()Akurasi validasi: 0.556 ± 0.157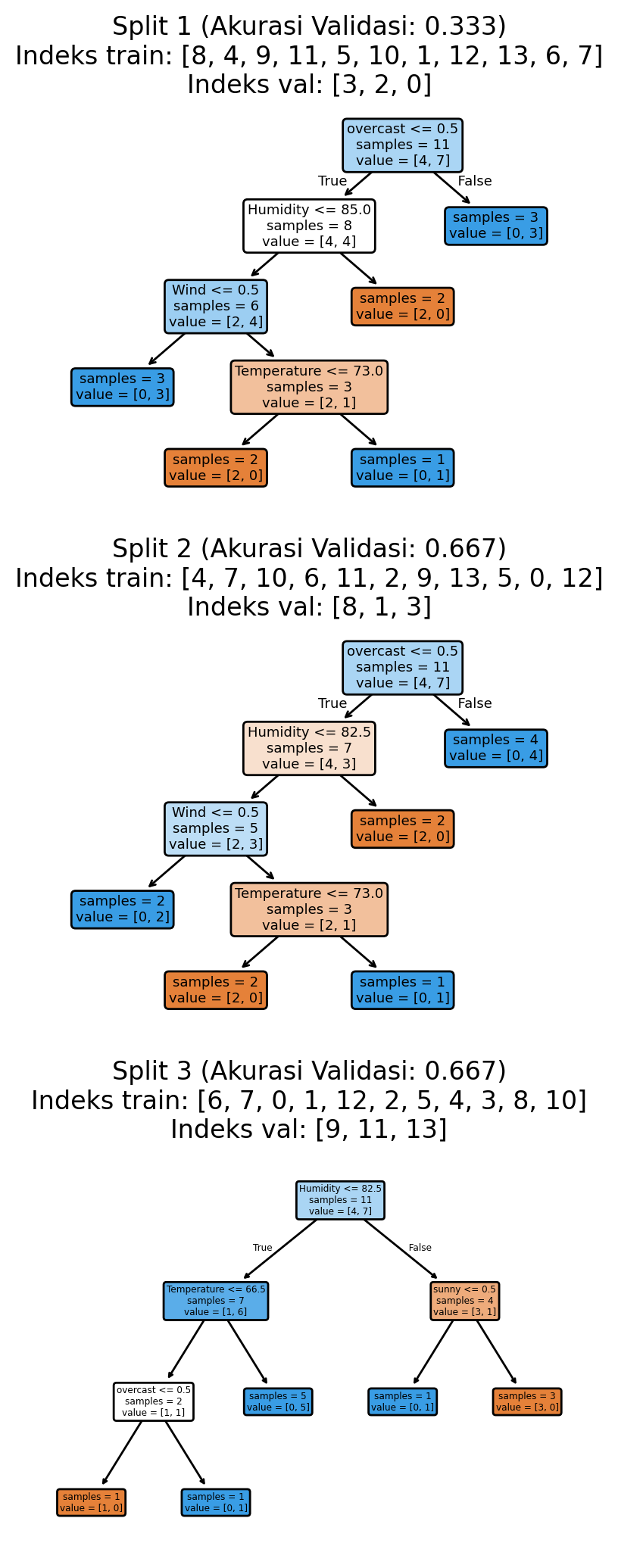
Namun, mencoba menjaga sifat acak dari pembagian dan campuran jenis data yang tepat secara bersamaan bisa jadi rumit. Metode ini terkadang harus membuat kompromi kecil antara menjadi sepenuhnya acak dan menjaga proporsi yang sempurna. Dalam penggunaan nyata, pertukaran kecil ini jarang menimbulkan masalah, dan memiliki set pengujian yang seimbang biasanya lebih penting daripada memiliki pembagian yang sepenuhnya acak.
5 🌟 Ringkasan Teknik Validasi & Kode Lengkap
Sebagai rangkuman, metode validasi model terbagi dalam dua kategori utama: metode hold-out dan metode cross-validation:
Metode Hold-out
- Train-Test Split: Pendekatan paling sederhana, membagi data menjadi dua bagian
- Train-Validation-Test Split: Pembagian tiga arah untuk pengembangan model yang lebih kompleks
Metode Cross-Validation
Metode K-Fold — Alih-alih satu pembagian, metode ini membagi data menjadi K bagian:
- Basic K-Fold
- Stratified K-Fold (menjaga keseimbangan kelas)
- Group K-Fold (mempertahankan pengelompokan data)
- Time Series Split (menghormati urutan waktu)
- Repeated K-Fold
- Repeated Stratified K-Fold
Metode Leave-Out — Metode ini membawa validasi ke tingkat ekstrem:
- Leave-P-Out: Menguji pada P titik data sekaligus
- Leave-One-Out: Menguji pada satu titik data
Metode Acak — Metode ini memperkenalkan keacakan yang terkontrol:
- ShuffleSplit: Membuat pembagian acak berulang kali
- Stratified ShuffleSplit: Pembagian acak dengan kelas yang seimbang
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import (
# Metode hold-out
train_test_split,
# Metode K-Fold
KFold, # K-fold dasar
StratifiedKFold, # Menjaga keseimbangan kelas
GroupKFold, # Untuk data berkelompok
TimeSeriesSplit, # Data temporal
RepeatedKFold, # Beberapa putaran
RepeatedStratifiedKFold, # Beberapa putaran dengan keseimbangan kelas
# Metode leave-out
LeaveOneOut, # Satu titik pengujian
LeavePOut, # P titik pengujian
# Metode acak
ShuffleSplit, # Pembagian train-test acak
StratifiedShuffleSplit, # Pembagian acak dengan keseimbangan kelas
cross_val_score # Hitung skor validasi
)
# Muat dataset (sama seperti sebelumnya)
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rainy', 'rainy', 'rainy', 'overcast',
'sunny', 'sunny', 'rainy', 'sunny', 'overcast', 'overcast', 'rainy',
'sunny', 'overcast', 'rainy', 'sunny', 'sunny', 'rainy', 'overcast',
'rainy', 'sunny', 'overcast', 'sunny', 'overcast', 'rainy', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0,
72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0,
88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0,
90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0,
65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True,
True, False, True, True, False, False, True, False, True, True, False,
True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes',
'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes',
'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df = pd.DataFrame(dataset_dict)
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
df['Wind'] = df['Wind'].astype(int)
X, y = df.drop('Play', axis=1), df['Play']
# Pembagian train-test sederhana
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, shuffle=False,
)
# Buat model
dt = DecisionTreeClassifier(random_state=42)
# Pilih metode validasi (aktifkan yang ingin digunakan):
#cv = KFold(n_splits=3, shuffle=True, random_state=42)
#cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
#cv = GroupKFold(n_splits=3) # Membutuhkan parameter groups
#cv = TimeSeriesSplit(n_splits=3)
#cv = RepeatedKFold(n_splits=3, n_repeats=2, random_state=42)
#cv = RepeatedStratifiedKFold(n_splits=3, n_repeats=2, random_state=42)
cv = LeaveOneOut()
#cv = LeavePOut(p=3)
#cv = ShuffleSplit(n_splits=3, test_size=0.2, random_state=42)
#cv = StratifiedShuffleSplit(n_splits=3, test_size=0.3, random_state=42)
# Hitung dan tampilkan skor
scores = cross_val_score(dt, X_train, y_train, cv=cv)
print(f"Akurasi validasi: {scores.mean():.3f} ± {scores.std():.3f}")
# Latih akhir & Uji
dt.fit(X_train, y_train)
test_accuracy = dt.score(X_test, y_test)
print(f"Akurasi test: {test_accuracy:.3f}")Akurasi validasi: 0.429 ± 0.495
Akurasi test: 0.714Catatan tentang hasil di atas: Kesenjangan besar antara akurasi validasi dan pengujian, bersama dengan standar deviasi yang sangat tinggi dalam skor validasi, menunjukkan performa model yang tidak stabil. Inkonsistensi ini kemungkinan berasal dari penggunaan validasi LeaveOneOut pada dataset cuaca kecil kita — menguji pada satu titik data menyebabkan performa bervariasi secara drastis. Metode validasi yang berbeda menggunakan set validasi yang lebih besar mungkin memberi kita hasil yang lebih andal.
6 Memilih Metode Validasi yang Tepat
Memilih cara memvalidasi model bukanlah hal yang sederhana — situasi yang berbeda membutuhkan pendekatan yang berbeda. Memahami metode mana yang harus digunakan bisa berarti perbedaan antara mendapatkan hasil yang andal atau menyesatkan. Berikut beberapa aspek yang perlu dipertimbangkan:
6.1 1. Ukuran Dataset
Ukuran dataset sangat memengaruhi metode validasi mana yang paling cocok.
Dataset Besar (lebih dari 100.000 sampel)
Ketika memiliki dataset besar, jumlah waktu pengujian menjadi salah satu pertimbangan utama. Validasi hold-out sederhana sering kali bekerja dengan baik karena memiliki cukup data untuk pengujian yang andal. Jika perlu menggunakan cross-validation, menggunakan hanya 3 fold atau ShuffleSplit dengan putaran lebih sedikit dapat memberikan hasil yang baik tanpa membutuhkan waktu terlalu lama.
Dataset Sedang (1.000 hingga 100.000 sampel)
Untuk dataset berukuran sedang, K-fold cross-validation biasa bekerja paling baik. Menggunakan 5 atau 10 fold memberikan keseimbangan yang baik antara hasil yang andal dan waktu komputasi yang wajar.
Dataset Kecil (kurang dari 1.000 sampel)
Dataset kecil, seperti contoh kita dengan 28 hari rekaman golf, membutuhkan pengujian yang lebih hati-hati. Leave-One-Out Cross-Validation atau Repeated K-fold dengan lebih banyak fold dapat bekerja dengan baik dalam kasus ini. Meskipun metode-metode ini membutuhkan waktu lebih lama untuk dijalankan, mereka membantu kita mendapatkan hasil yang paling andal ketika tidak memiliki banyak data.
6.2 2. Sumber Daya Komputasi
Ada keseimbangan tiga arah antara ukuran dataset, kompleksitas model, dan metode validasi yang digunakan.
Model yang Cepat Dilatih
Model sederhana seperti decision tree, logistic regression, dan linear SVM dapat menggunakan metode validasi yang lebih menyeluruh seperti Leave-One-Out Cross-Validation atau Repeated Stratified K-fold karena pelatihan yang cepat.
Model yang Butuh Sumber Daya Besar
Deep neural network, random forest dengan banyak pohon, atau model gradient boosting membutuhkan waktu pelatihan jauh lebih lama. Saat menggunakan model ini, metode validasi yang lebih intensif seperti Repeated K-fold atau Leave-P-Out mungkin tidak praktis. Kita mungkin perlu memilih metode yang lebih sederhana seperti K-fold dasar atau ShuffleSplit.
Pertimbangan Memori
Beberapa metode seperti K-fold perlu melacak beberapa pembagian data sekaligus. ShuffleSplit dapat membantu mengatasi keterbatasan memori karena menangani satu pembagian acak pada satu waktu.
6.3 3. Distribusi Kelas
Ketidakseimbangan kelas sangat memengaruhi cara kita memvalidasi model. Dengan data yang tidak seimbang, metode validasi terstratifikasi menjadi sangat penting. Metode seperti Stratified K-fold dan Stratified ShuffleSplit memastikan setiap pembagian pengujian memiliki campuran kelas yang kira-kira sama dengan dataset lengkap kita.
6.4 4. Data Time Series
Saat bekerja dengan data yang berubah seiring waktu, kita memerlukan pendekatan validasi khusus. Metode pembagian acak biasa tidak bekerja dengan baik karena urutan waktu sangat penting. Dengan data deret waktu, kita wajib menggunakan metode seperti Time Series Split yang menghormati urutan waktu.
6.5 5. Ketergantungan Kelompok
Banyak dataset mengandung kelompok-kelompok data yang saling terkait secara alami. Koneksi-koneksi dalam data kita ini memerlukan penanganan khusus saat memvalidasi model. Ketika titik data saling berhubungan, kita perlu menggunakan metode seperti Group K-fold untuk mencegah model secara tidak sengaja mempelajari hal-hal yang tidak seharusnya.
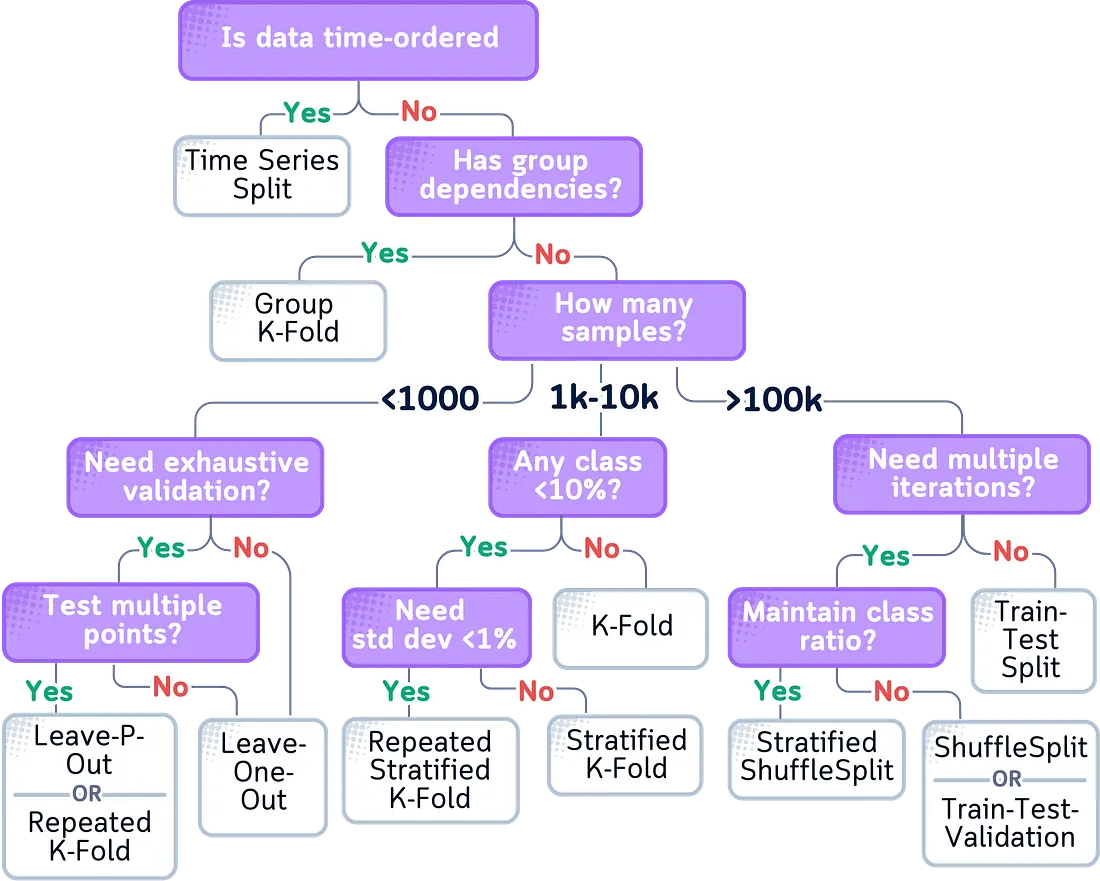
6.6 Panduan Praktis
Berikut adalah panduan alur untuk memilih metode validasi yang paling sesuai dengan data Anda:
7 Penutup
Validasi model sangat penting untuk membangun model machine learning yang andal. Setelah menjelajahi banyak metode validasi, dari pembagian train-test sederhana hingga pendekatan cross-validation yang kompleks, kita telah belajar bahwa selalu ada metode validasi yang sesuai untuk data apa pun yang kita miliki.
Meskipun machine learning terus berkembang dengan metode dan alat baru, aturan dasar validasi ini tetap sama. Ketika memahami prinsip-prinsip ini dengan baik, saya yakin Anda akan membangun model yang dapat dipercaya dan diandalkan oleh semua orang.
8 Bacaan Lanjutan
Untuk penjelasan rinci tentang metode validasi di scikit-learn, pembaca dapat merujuk pada dokumentasi resmi, yang menyediakan informasi komprehensif tentang penggunaan dan parameternya.
9 Lingkungan Teknis
Artikel ini menggunakan Python 3.7 dan scikit-learn 1.5. Meskipun konsep yang dibahas umumnya berlaku, implementasi kode spesifik mungkin sedikit berbeda dengan versi yang berbeda.